webpack中文文档
webpack解说版本一
1、webpack管理pageage的好处
很早之前,我们引用第三方依赖的方式,是通过script标签引入,这会有以下几个问题:
- 需要确保依赖下载完成之后才能使用
- 需要确保依赖的引入顺序
- 引入的依赖如果没有被使用,浏览器也会下载,占带宽
- 第三方依赖发生变化后,需要重新引入新的url地址
因此,我们用webpack来管理这些脚本,从而解决以上的痛点
- 包管理器负责依赖的安装
- package.json定义项目需要的各种模块及项目的配置信息
# 可以指定具体的构建配置参数,如下
$ npx webpack --config webpack.config.js
注意:如果 webpack.config.js 存在,则 webpack 命令将默认选择使用它。我们在这里使用 --config 选项只是向你表明,可以传递任何名称的配置文件。这对于需要拆分成多个文件的复杂配置时非常有用。
开始之前先了解一下resolve
resolve配置如何解析模块,例如当你import 'lodash'时,resolve选项会改变webpack去查找lodash模块的位置。
module.exports = {
//...
resolve: {
// 更多配置规则https://webpack.js.org/configuration/resolve/#resolve-alias
alias: {
app: path.resolve(__dirname, 'src/app/'),
},
// 一个模块可能适用于多端(比如浏览器,或者node端),所以当引入一个模块时,也会针对不同的环境提供对应的文件
// 而这里的字段是和要引入的包里对应package.json对应的。
aliasFields: ['browser']
//如果为真,则不允许使用无扩展名文件
enforceExtension: false
// 是否要求对模块使用扩展(例如加载器),默认fasle
enforceModuleExtension: false,
// 使用这个将覆盖默认选项,因此为防止错误,最好加个"*"
// 自动解析某些扩展,默认情况如下
extensions: ['.wasm', '.mjs', '.js', '.json'],
// 默认如下,当从npm包里导入时,如导入d3,这个选项将对应d3包里的package.json里该字段
// 感觉有点类似aliasFields?
mainFields:['browser', 'module', 'main']
// 告诉webpack在解析模块时应该搜索什么目录,默认为node_modules
modules:['node_modules']
// 如果想早于node_modules,只需在数组前加入即可,如
modules:[path.resolve(__dirname, 'src'),'node_modules']
// 启用,会主动缓存模块,但并不安全。传递 true 将缓存一切。默认
unsafeCache: true
// 与上面resolve属性集相同,但仅用于解析webpack的loader,默认如下
resolveLoader: {
modules: [ 'node_modules' ],
extensions: [ '.js', '.json' ],
mainFields: [ 'loader', 'main' ]
// 这不是resolveLoader的默认值
// 从webapck2开始强烈建议使用完整的loader名,如example-loader
// 如果不想完整,则可配置如下
moduleExtensions: [ '-loader' ]
}
}
}
对于resolve.modules,绝对路径和相对路径都能使用,但是要知道它们之间有一点差异。通过查看当前目录以及祖先路径(即 ./node_modules, ../node_modules 等等),相对路径将类似于 Node 查找 node_modules 的方式进行查找。使用绝对路径,将只在给定目录中搜索。
2、webpack输入与输出
以下会在dist目录生成一个名为mainName.js的文件。
const path = require('path')
module.exports = {
// 默认是production,代码压缩丑化
mode: 'development',
entry: {
mainName: './src/index.js'
},
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'dist')
}
}
以下会在dist目录生成一个名为main.js的文件。
const path = require('path')
module.exports = {
mode: 'development',
entry: './src/index.js',
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'dist')
}
}
综上:默认情况下会构建出一个名为main的js文件,除非自定义文件名(如上的mainName)。然后在output里面[name]就是取自entry定义的名字。
上面的[name]其实就是内置的name变量,这时可以把它看作一个字符串模板函数,每个要输出的文件(也叫chunk)都会通过这个函数去拼接出要输出的文件名称。
内置变量除了上面的name,还有下面几个:
id: chunk的唯一标识,从0开始(但我这里打印的依然是:main)name: chunk的名称hash:compilation对象的hash值chunkhash:chunk内容的hash值
其中hash和chunkhash的长度是可指定的,如[hash:8]代表8位的hash值,默认是20位。
-
[hash] is replaced by the hash of the compilation.- compilation对象针对的是随时可变的项目文件,只要文件有变动,就会重建
- hash是compilation对象计算所得,可以理解为项目总体文件的hash值
- 因此当输出很多文件时,你肯定不想因为一个文件的改变,把所有其他文件的文件名都改变了。。。
-
[chunkhash] is replaced by the hash of the chunk.- 代表具体模块(chunk)的hash值
- 当输出多文件,同时想利用缓存,[chunkhash]无疑是最佳选择
但hash与chunkhash一块使用会报错,如下:
const path = require('path')
module.exports = {
// 默认是production,代码压缩丑化
mode: 'development',
entry: './src/index.js',
output: {
// [hash].[contenthash].js也会报错,
// 若开启HMR,关闭后重试或许可解决(只需注释HMR模块插件)
filename: '[hash].[chunkhash].js',
path: path.resolve(__dirname, 'dist')
}
}
// 错误信息
// ERROR in chunk main [entry]
// [hash][chunkhash].js
// Cannot use [chunkhash] or [contenthash] for chunk in '[hash][chunkhash].js' (use [hash] instead)
注意:webpack编译的文件入口是js文件,不支持其他类型的文件, 因此要编译style文件,需要将其导入到js文件中然后再编译。但这样会造成一个问题,就是此时无论修改style文件还是js文件,都会导致chunkhash改变,因为将style样式文件打包到js文件里了,因此此时可以配合插件extract-text-webpack-plugin提供的contenthash来解决,表示文本内容的hash值,也就是只有style文件hash值。
3、webpack管理资源
在webpack之前,我们利用grunt和gulp来处理资源,并将它们从 /src 文件夹移动到 /dist 或 /build 目录中。同样方式也被用于 JavaScript 模块,但是,像 webpack 这样的工具,将动态打包(dynamically bundle)所有依赖项(创建所谓的依赖图(dependency graph))。这是极好的创举,因为现在每个模块都可以明确表述它自身的依赖,我们将避免打包未使用的模块。
还可以通过loader来引入任何其他类型的文件
3.1、处理css等样式文件’
参考1
参考2
现在推荐使用mini-css-extract-plugin
webpack加载css,sass,less等资源并集成postcss
我们要知道,webpack从入口文件开始解析,然后遇到各种类型的资源会尝试寻找对应的loader规则,匹配上了就使用相应的loader处理,处理完再输出到指定目录。然后我们的页面引用的最终文件也是打包完成的,因此如果某些资源处理的不对,页面就会出现错误,同时构建日志会报错。。。
处理样式文件配置流程应为:
- 安装
npm i -D style-loader,css-loader - 配置webpack匹配css规则
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader','css-loader']
}
]
}
- 编辑css文件,引入并使用
其中style-loader插件作用是在最终页面插入style标签,同时自动引入对应的css文件。而且还要在页面中查看(不要检查页面源代码,因为它不会显示结果),查看head标签,就可以看到style标签。
疑问?在不使用分离插件时,css文件被打包到了main.js文件里,👆的过程是如何实现的?
答:将原生的css文件打包成js文件时,会在js文件中生成很多额外的函数,用于在运行时将css注入到style标签里。这就会造成文件臃肿,如一个1KB的未被压缩的CSS文件生成的对应的js文件大约有16KB,这导致了输出文件过于庞大,影响传输速度。
先来看看如何分离css,这里用到插件extract-text-webpack-plugin,因此先安装,然后增加配置如下:
// 插件使用:https://webpack.docschina.org/plugins/extract-text-webpack-plugin/
const ExtractTextPlugin = require('extract-text-webpack-plugin')
module.exports = {
module: {
rules: [
{
test: /\.css$/,
// ExtractTextPlugin.extract(options: loader | object)
use: ExtractTextPlugin.extract({
// 应用于没有被提取的css
fallback: 'style-loader',
use: 'css-loader'
})
}
]
},
// 注册插件
plugins: [
// 实例化插件,ExtractTextPlugin(option: filename | object)
new ExtractTextPlugin('style.css')
]
}
注意在webpack4中,若直接npm i -D extract-text-webpack-plugin,然后配置如上,构建时会报错Error: Chunk.entrypoints: Use Chunks.groupsIterable and filter by instanceof Entrypoint instead
答:可以安装时添加@next解决(因为当前版本不支持webpack4.0.0以上版本)。
如上处理时优缺点如下:
优点 更少 style 标签 (旧版本的 IE 浏览器有限制,IE8有上限)
缺点 额外的 HTTP 请求
优点 CSS SourceMap (使用 devtool: "source-map" 和 extract-text-webpack-plugin?sourceMap 配置)
缺点 css字符串转为style需要更长的编译时间,
优点 CSS 请求并行
缺点 没有运行时(runtime)的公共路径修改
优点 CSS 单独缓存
缺点 没有热替换
优点 更快的浏览器运行时(runtime) (更少代码和 DOM 操作)
缺点 ...
extract-text-webpack-plugin插件还有不同的参数选项,点击查看插件详情
当然插件extract-text-webpack-plugin可以分离各种被匹配的资源,但经过上面处理后,文件是被分离出来了,但style-loader失效了???
答:单纯使用分离插件会使得热更新失效,因为每次生成的文件名都会变(这句说辞待完善),因此要么手动每次引入,要么就是借助html-webpack-plugin插件
再来深入理解一下css-loader
css-loader解释(interpret)@import和url(),会import/require()后解析(resolve)他们。
{
loader: "css-loader",
option: {
// 对于以/开头的url,默认行为是不转译,即url(/image.png) => url(/image.png)
// 若设置了root,则会添加到url前面,然后再转译。如:url(/image.png) => require('./image.png')
// 不建议用相对路径
root: '.',
// 是否禁用css-loader解析url(),
// 如果false不解析,则原样输出url的内容,会导致路径错误
url:true,
// 遵循与webpack的resolve.alias相同的语法
// 当使用第三方的样式包时,会非常方便,如下
alias:{
"../fonts/bootstrap": "bootstrap-sass/assets/fonts/bootstrap"
},
// 要禁用css-loader解析@import,可以设置为false,
// 禁用之后,@import 方式导入的模块都将失效
import: true,
// 是否启用局部作用域css。
module: true,
// 默认情况下,css将所有的类名暴露到全局的选择器作用域中。样式可以在局部作用域中
module: true,
// 默认情况下,如果模块系统指定,css-loader 将压缩 css
// 在某些情况下,压缩对于 css 来说是破坏性的,所以如果需要设置,可以向基于 cssnano 的 minifier(cssnano-based minifier) 提供自己的选项
minimize: true || {/* CSSNano Options */},
// 默认情况下不启用它们,因为它们会导致运行时的额外开销,并增加了 bundle 大小 (JS source map 不会)。
sourceMap: false
// 一般情况下,css样式的类名都是-连接,如果想经过css-loader处理后,使用驼峰,可以设置该选项
// 如file.css为.class-name {} 可以这样 import { className } from 'file.css';
camelCase:true
}
}
3.2、处理图片类文件
页面需要的图片类文件一般都是用相对路径引用,或使用vue中的资源路径处理。
先来看看webpack上关于解析图片路径的原理:
当使用 import myImg from './xxx/my-img.png引入图像时,webpack会利用file-loader处理图片并输出到output目录,并且用myImg变量指向该图片处理后的最终url。当使用 css-loader 时,如上所示,你的 CSS 中的 url(‘./my-img.png’) 会使用类似的过程去处理。loader 会识别这是一个本地文件,并将 ‘./my-image.png’ 路径,替换为输出目录中图像的最终路径。html-loader 以相同的方式处理 <img src="./my-image.png" />。
file-loader生成的文件名就是文件内容的md5哈希值并会保留所引用资源的原始扩展名。
再来看看vue中说的:
例如,url(./image.png) 会被转换为 require('./image.png')
而<img src="../image.png">会被编译为
createElement('img', { attrs: { src: require('../image.png') }})
处理图片步骤:
1、 安装npm i -D file-loader
2、 配置webpack匹配图片规则
module:{
rules:[
{
// 要熟记常用正则的用法
test: /\.(png|svg|jpe?g|gif)$/,
// use是数组,子元素可以是字符串,可以是对象
use: [
{
loader: 'file-loader',
options: {
name (file){
// [name] type: String default: file.basename
// [path] type: String default: file.dirname
// 这里的[name][path]都是插件提供的
if(env === 'development'){
return '[path][name].[ext]'
}
// hash默认算法是md5,处理的值是文件内容,意味着不是每次编译都变,因为内容不变
return '[hash].[ext]'
}
}
}
]
}
]
}
3、 编辑图片文件,引入并使用
// 可以直接这样引入图片,并直接使用
import myImg from './my-img.png'
const newImg = new Image()
newImg.src = myImg
document.appendChild(newImg)
注意在上述操作后,图片路径少个/dist/,因此找不到图片…
答:index.html的位置应该和dist在同一个目录
上面说到file-loader,其实还有url-loader,这两个loader功能相似,只是后者可以设置阈值,当小于阈值时返回DataURL格式的路径。其实DataURL是没有路径可言的,本身就是一个图片资源。
配置如下:
module: [
{
test: /\.(png|jpe?g|svg|gif)$/,
use: [
{
loader: 'url-loader',
option: {
// 小于10k的转换为dataURL格式
limit: 10000,
// 浏览器通常使用MIME类型(而不是文件扩展名)来确定如何处理文档,终端:file xxx查看
// 由类型与子类型两个字符串中间用'/'分隔而组成
// 这里是指定要转换成的dataurl的文件子类型,需要用到jimp插件(专门修改资源mime类型)
mimetype: 'image/png',
// 大于limit的先经过fallback处理,若无fallback则交由file-loader处理
fallback: 'responsive-loader'
// 还可以设置处理的质量
quality: 85,
// 可以设置name
name: '[hash:8].[ext]'
}
}
]
}
]
上面显式的,分别使用了file-loader或者url-loader,如果二者同时使用,则会把url-loader处理的结果再输出到dist目录,也就是说,url-loader处理生成的图片(普通url)或dataURL图片,file-loader会将这些详细信息再输出到dist目录。
注意:上面操作生效的前提是,在配置文件里file-loader优先配置,也就是说和顺序有关。
比如:url-loader处理生成的图片文件名为:020f95e5.png
然后经过file-loader处理会输出一个新文件如:1bae1637.png,图片里的内容为:module.exports = __webpack_public_path__ + "020f95e5.png";
注意文件名
注意:经过上面的处理,文件内容变成了代码,就不是有效的图片格式,也就打不开了。
还可以如下连续用多个配置
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: [ 'style-loader', 'css-loader' ]
},
{
test: /\.(png|jpg|gif|svg|eot|ttf|woff|woff2)$/,
loader: 'url-loader',
options: {
limit: 10000
}
}
]
}
}
对于生产环境还可以:
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: env === 'production'
? ExtractTextPlugin.extract({
fallback: 'style-loader',
use: [ 'css-loader' ]
})
: [ 'style-loader', 'css-loader' ]
},
]
},
plugins: env === 'production'
? [
new ExtractTextPlugin({
filename: '[name].css'
})
]
: []
}
3.3、处理js文件
本地利用babel编译es6至es5
1、 初始化仓库 npm init
2、 配置.babelrc
只有配置了相关的预处理插件,babel才知道将高级语法转译到什么类型,若不配,则原样输出
{
"presets": [
// 预处理的版本,需要安装对应的插件
"env",
// 如果想体验初步规范的新语法,可以增加这个
// "stage-2"
],
}
3、 安装.babelrc配置的预处理版本及babel
npm i -D babel-cli babel-preset-env
4、 将含有m1.js,m2.js的文件夹编译打包,配置package.json
这里你或许会问,直接在项目里运行babel命令不就好了,为何还要写在这里?因为你安装的babel-cli只是项目内,并没有全局安装,因此会提示:command not found : babel
{
"scripts": {
"build": "babel src -d dist"
},
}
5、 终端运行编译后的文件即可
综上: 上面处理了css,图片等文件类型,其实还可以加载字体类型,数据类型(如:json文件,csv,tsv和xml等),原理都是相似的。类似于 NodeJS,JSON 支持实际上是内置的,也就是说 import Data from ‘./data.json’ 默认将正常运行。要导入 CSV、TSV 和 XML,你可以使用 csv-loader 和 xml-loader。
上面只说了很简单的一种使用方式,其实还有很多相关的使用方式,更多详情参考:
babel官网中文文档
babel7使用手册
这里简短总结一下babel是如何读懂你的代码的
使用webpack处理源代码过程中,babel负责的功能很纯粹,就是接收字符串格式的代码,然后返回一段新的代码字符串(及sourcemap),就是个编译器,将高级语法转译成低级语法,不会运行代码,也不会打包。。。
上面的过程分为三个过程:
- parser(解析)
- 分词(词法分析)
- 语法分析
- transform(转换)
- generate(生成)
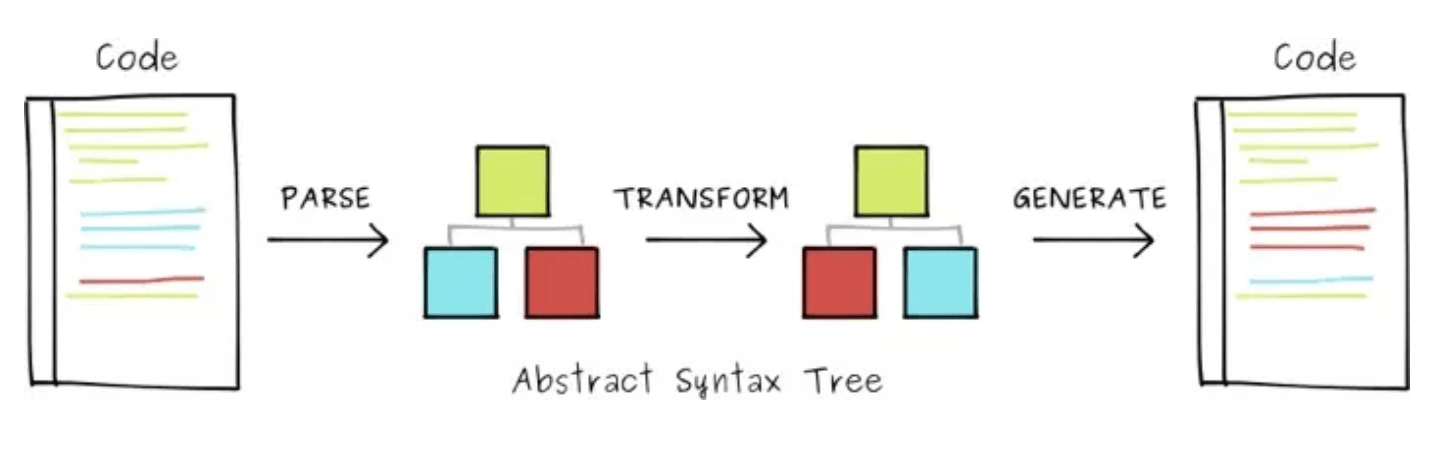
1、 parser(解析)
比如代码块n*n经过分词之后,会变成类似如下:
// 词法分析阶段把字符串形式的代码转换为 令牌(tokens)流
// 每个type有一组属性来描述该令牌流,就是用来说明该令牌流的详细信息
// 分词有一定的规则,也就是将js代码分割成最小的语法单元
[
{ type: { ... }, value: "n", start: 0, end: 1, loc: { ... } },
{ type: { ... }, value: "*", start: 2, end: 3, loc: { ... } },
{ type: { ... }, value: "n", start: 4, end: 5, loc: { ... } },
...
]
分词之后,在语法分析阶段会将令牌流转换成初步AST的形式,其实可以理解成一个大的json对象(对象形式描述的令牌流),便于后续的操作。。。
2、 transform(转换)
转换阶段接收第一步生成的初步AST对象,然后对其遍历,在此过程中对节点进行添加,更新或移除等(比如本来是箭头函数的描述符,修改成普通的函数描述符,就完成箭头函数转化的一步。因为初步AST有详细的描述符,所以只需修改描述符就可以完成对应的语法修改),这也是各种编译插件介入的地方。。。
3、 generate(生成)
这个阶段接收上一步经过一些列转换之后的AST对象,然后再转换成字符串形式的代码,同时创建源码映射(source map)。其实原理很简单,就是深度遍历整个AST,然后构建可以表示转换后的字符串。
更多详情参考:
Babel是如何读懂JS代码的(AST)*
AST抽象语法树——最基础的javascript重点知识,99%的人根本不了解
AST初学者教程
抽象语法树(abstractSyntaxTree)
AST in Modern JavaScript
4、自动更新引入的文件
上面我们在index.html写死了引入的文件名如<script src="main.js"></script>,但如果我们更改了入口名或增加了入口数量,那岂不是每次都得手动改这个index.html。。。
通过html-webpack-plugin解决上面的问题,这个插件的作用就是在每次compilation发生变化时,都会重新生成html文件。
引入插件步骤:
npm i -D html-webpack-plugin- 增加
webpack.config.js配置如下const HtmlWebpackPlugin = require('html-webpack-plugin') module.exports = { plugins: [ new HtmlWebpackPlugin({ title: 'output Management', // 默认index.html,还可以加子目录:assets/admin.html filename: 'my-index.html' }) ] }经过html-webpack-plugin插件的处理,不但修复了使用分离css插件后style-loader失效的问题,还每次都重新生成index.html。因此这时把整个dist目录删除了也没问题了。而且生成的index.html就已经包含了各种标签。。。
注意如果你在output里配置了publicPath,则在使用html-webpack-plugin生成的html文件里生成的引用文件路径前缀就是publicPath了
5、定制输出模板
到这里你应该思考,这个index.html应该是某个模板文件生成,那既然如此,是不是可以定制这个模板呢,没错就是html-webpack-template,安装然后增加配置如下即可使用:
const HtmlWebpackTemplatePlugin = require('html-webpack-template')
module.exports = {
plugins: [
new HtmlWebpackPlugin({
// required 必填选项
inject: false,
template: HtmlWebpackTemplatePlugin
// template: './src/index.html' //还可以自定义模板
// Optional 选填选项
title: 'output Management',
filename: 'my-index.html',
// 还可以增加meta等等标签
meta: [
{
name: 'description',
content: 'A better default template for html-webpack-plugin.'
}
],
})
]
}
注意:这样意味着,可以根据业务需求自定义模板,可以灵活加以应用。。。
6、插件删除dist目录
到目前为止,dist目录里的文件,一直都是手动删除,这不符合程序猿懒的特质,因此clean-webpack-plugin需要了解一下:
const CleanWebpackPlugin = require('clean-webpack-plugin')
module.exports = {
plugins: [
// new CleanWebpackPlugin(paths [, {options}])
// 参数一:paths是数组或字符串,数组的话可以匹配多个
// 参数二:paths配置相关的配置
new CleanWebpackPlugin(['dist','build/*.*','web/*.js'],{
// __dirname脚本执行的目录
root: __dirname
})
]
}
7、webpack管理资源的原理
你可能会感兴趣,webpack及其插件似乎“知道”应该哪些文件生成?
答案是,通过 manifest,webpack 能够对「你的模块映射到输出 bundle 的过程」保持追踪。这里我们只需知道,webpack背后通过一定的策略来控制模块间的交互。。。(待完善)
8、开发环境配置
- scource map
- webpack’s Watch Mode
- webpack-dev-server
- webpack-dev-middleware
以上我们在修改一个文件以后,需要重新构建,然后刷新浏览器才能看到效果,这在开发环境下无疑是繁琐且笨拙的,这里我们说说开发环境配置。。。
1. scource map
当使用webpack打包文件以后,一般会将很多模块打包到一个文件里,因此当具体某个文件错误时debug将变得异常困难,只能粗略的指向打包出来的那个大文件,而无法准确定位到源代码的具体位置,因此scource map就需要了解一下
source map,它是一个信息文件,里面存储着位置信息。也就是说,转换后的代码的每一个位置,所对应的转换前的位置。不过目前好像只有chrome浏览器支持(在开发者工具的setting中开启Enable source maps)
在开启source map后,打包出来的文件底部会有类似//@ sourceMappingURL=/path/to/file.js.map这样的内容,意思是说,具体的map文件在/path/to/file.js.map这里。
只需在webpack.config.js添加下面代码即可
module.exports = {
// devtool有很多选项,这里说几项,详情参考:https://webpack.docschina.org/configuration/devtool
// 打包出来的文件底部有sourceMappingURL字样,点击错误定位到的是没经处理的源码位置
devtool: 'source-map'
// 打包出来的文件底部没有sourceMappingURL字样,点击错误定位到的是压缩后的代码位置
// 此时dist目录里有map文件
devtool: 'hidden-source-map'
// 和上面不同的是,该模式生成的文件不但有sourceMappingURL字样,而且把具体的map文件内容内联在打包的文件里了,而前两者sourceMappingURL的值只是一个地址
// 注意此时dist目录没有map文件,因为相当于将map文件内敛到chunk里了,但这样会使得打包出来的文件变大
devtool: 'inline-source-map'
}
避免在生产中使用 inline-* 和 eval-*,因为它们可以增加 bundle 大小,并降低整体性能。 更多请参考:
滴滴出行说devtool的几种模式
阮一峰-sourceMap详解
当然打包处理的代码有很多优点:
- 压缩混淆
- 多个文件合并,减少http请求
- 将其他类型文件编译成js,如ts
注意:一般情况下sourceMap的值是Boolean型,表示是否开启sourceMap。。。但具体是哪种sourceMap,则是devtool的值。
2. [webpack’s Watch Mode]
现在我们每次修改都需要重新构建,并刷新浏览器才能看到结果,这在开发过程中很繁琐,因此我们可以添加watch模式,也就是webapck会自动开启watch模式观察依赖图中的所有的文件,当文件发生变化时,就自动重新构建。。。
修改package.json的scripts如下,然后运行npm run watch即可:
{
"scripts": {
"watch": "webapck --watch",
"build": "webpack"
},
}
注意点虽然自动重建,但仍然需要刷新浏览器才可以看到效果
在watch模式下,虽然可以监听文件的变动并自动构建,但需要刷新浏览器才可以,因此我们需要借助webpack-dev-server来帮我们自动刷新浏览。(可以先思考一下,watch模式下,webpack监视的原理是什么?)
webpack-dev-server提供了一个web服务器,并能够自动重新加载,同样需要先安装。
注意:此时是重新加载也就是liveReload,是重新加载整个页面。。。
npm i -D webpack-dev-server
然后配置webpack服务器监视哪个目录下的文件变动,因为watch模式下已经将变化的文件重新构建并输出到dist目录了,当然devServer肯定集成了watch。。。增加配置文件如下:
// 和entry等同等级
devServer: {
// 推荐用绝对路径;值为false时表示禁用(此时遍历的目录是?);数组时表示多个目录
contentBase: path.join(__dirname, "dist"),
// 当启用 lazy 时,dev-server 只有在请求时才编译包(bundle)。这意味着 webpack 不会监视任何文件改动。
lazy: true
// 使用 filename,可以只在某个文件被请求时编译。
filename:'boundle.js',
// 在所有响应中添加首部内容:
headers: {
"X-Custom-Foo": "bar"
}
},
再修改package.json文件如下:
{
"scripts": {
"dev": "webpack-dev-server --open",
"watch": "webapck --watch",
"build": "webpack"
},
}
上面的配置–open是说当第一次构建时,自动打开浏览器,当后续修改文件了,会自动构建并重新刷新浏览器。。。
注意:这里的构建只是发生在内存中,并没有dist目录生成,这些看不见的工作webpack在后台处理(详情看devServer原理)。
使用了webpack-dev-server虽然可以自动构建并自动重新加载,但是整个页面的重新加载,浪费资源。因此需要用到模块热替换(Hot Module Replacement 或 HMR)
模块热替换(Hot Module Replacement 或 HMR)
HMR也就是在程序运行的时候替换,添加或删除模块,而无需重新加载整个页面。。。相比LiveReload而言,只刷新改变的部分。
开启HMR的两种方式:
- 当使用了webapck-dev-server后,可以在配置了
hot:true以后,还需要实例化HotModuleReplacementPlugin插件,这是webpack内置插件plugins: [ // 为了更容易查看要修补(patch)的依赖 new webpack.NamedModulesPlugin(), new webpack.HotModuleReplacementPlugin() ] - 通过命令行实现,如修改脚本
webpack-dev-server --open --hot
哪些方式加快开发速度:
- 保留在完全重新加载页面时丢失的应用程序状态。
- 只更新变更内容,以节省宝贵的开发时间。
- 调整样式更加快速 - 几乎相当于在浏览器调试器中更改样式。
HMR监听js文件变动
HMR是热模块替换,当主文件引用了另一个js文件,当这个js文件发生变化时,可以将这个变化的文件传递给module.hot这个属性下的accept接口。也就是说,通过HotModuleReplacementPlugin插件开启了HMR以后,同时还提供一些相关接口,这些接口可以接受依赖模块的更新,并触发一个回调函数。还可以获取模块热替换进程的状态等信息。。。如下:
if(module.hot){
// 当更新lazy.js文件后,会在控制台打印module is updated...
module.hot.accept('./views/lazy',function(){
console.log('module is updated...');
})
}
注意:监听的这个js文件不能作为入口,参考启用HMR
HMR监听样式文件变动
此前说过style-loader,其实当更新css依赖模块时,此loader在后台使用module.hot.accept来修补(patch) <style>标签。
此处出现了patch,意思是修补,可以理解为更新的意思。另外如果此时像监听js一样监听css,则不会触发如下:
if(module.hot){
// 此时更新style.css,则不会触发回调。。。猜测是被style-loader拦截了
module.hot.accept('./views/style.css',function(){
console.log('css module is updated...');
})
}
综上:
HMR 是可选功能,只会影响包含 HMR 代码的模块。举个例子,通过 style-loader 为 style 样式追加补丁。 为了运行追加补丁,style-loader 实现了 HMR 接口;当它通过 HMR 接收到更新,它会使用新的样式替换旧的样式。
类似的,当在一个模块中实现了 HMR 接口,你可以描述出当模块被更新后发生了什么。然而在多数情况下,不需要强制在每个模块中写入 HMR 代码。如果一个模块没有 HMR 处理函数,更新就会冒泡。这意味着一个简单的处理函数能够对整个模块树(complete module tree)进行更新。如果在这个模块树中,一个单独的模块被更新,那么整组依赖模块都会被重新加载。
4. webpack-dev-middleware
webpack-dev-middleware 是一个容器(wrapper),他可以把webpack处理后的文件传递给一个服务器(server)。webpack-dev-server在内部使用了它,它也可以作为一个单独的包来使用,接下来我们配合express来使用它。
1、 npm i -D express webpack-dev-middleware
2、 增加webpack.config.js里output的publicPath
output: {
filename: '[name].js',
// 这个只是本地硬盘上的路径
path: path.resolve(__dirname, 'dist'),
// 所有通过html-webpack-plugin插件插入到页面的资源,前缀都会添加/spa/,如果是/spa,则是/spaxxx
// 绝对路径则会拼接上服务名,很少用相对路径
// 完整的路径如https://www.baidu.com,一般是将资源托管到第三方平台
publicPath: '/spa/'
}
3、 增加服务器文件。
const express = require('express')
const webpack = require('webpack')
const webpackDevMiddleware = require('webpack-dev-middleware')
const app = express()
const config = require('./webpack.config.js')
const compiler = webpack(config)
// 将webpackDevMiddleware插件挂载在express上,用webpack.config.js的配置路径来配置服务器的地址
app.use(webpackDevMiddleware(compiler, {
publicPath: config.output.publicPath
}))
app.listen(3000, function(){
console.log('server is running : http://localhost:3000')
})
4、 在package.json里增加
"scripts": {
"server": "node server.js"
}
5、 启动服务npm run server
这时你会发现访问http://localhost:3000失败,因为我们给服务配置了publicPath,因此需要访问http://localhost:3000/spa/
总结 webpack-dev-middleware的作用是生成一个与wabpack的compiler绑定的中间件,然后在express启动的服务上调用这个中间件。
webpack-dev-middleware插件作用主要有三点:
- 通过watch mode,监听资源的变更,然后自动打包
- 快速编译,走内存
- 返回中间件,支持express的use格式
特别注明:webpack明明可以用watch mode,可以实现一样的效果,但是为什么还需要这个中间件呢?
答:,第二点所提到的,采用了内存方式。如果,只依赖webpack的watch mode来监听文件变更,自动打包,每次变更,都将新文件打包到本地,就会很慢。而webpack-dev-middleware插件每次构建及打包都是在内存中完成,意味着此时不会生成dist
9、tree shaking
随着项目越来越大,项目里可能会引入大量用不到的模块,如果这些模块都打包到chunk里,势必造成带宽浪费,因此需要一种手段将其清除,也就是tree shaking
新的 webpack 4 正式版本,扩展了这个检测能力,通过 package.json 的 “sideEffects” 属性作为标记,向 compiler 提供提示,表明项目中的哪些文件是 “pure(纯的 ES2015 模块)”,由此可以安全地删除文件中未使用的部分。
9.1、tree shaking原理
tree shaking是一个术语,通常用于描述移除js上下文中的未引用代码(dead-code)。它依赖于es6模块系统的静态结构特性,例如 import 和 export。这个术语和概念实际上是兴起于 ES2015 模块打包工具 rollup。
你可以将应用程序想象成一棵树。绿色表示实际用到的源码和 library,是树上活的树叶。灰色表示无用的代码,是秋天树上枯萎的树叶。为了除去死去的树叶,你必须摇动这棵树,使它们落下。
Es6引入自己的模块格式的一个原因是为了支持静态结构,有以下几个好处。
- dead code elimination during bundling
- 加载打包后的文件,可以检索更少的文件
- 压缩打包后的文件,比压缩单独的文件更有效
- bunding过程中可以删除dead code
- compact bundling, no custom bundle format
- 它们的静态结构意味着 bundle 格式不必考虑有条件加载的模块
- 导入是导出的只读视图,这意味着您不必复制导出,可以直接引用它们
- faster lookup of imports (更快的查找导入)
- es6模块导入的库,可以静态的知道并优化
- variable checking (检查变量)
- 静态模块结构,您总是静态地知道哪些变量在模块内的任何位置都是可见的
- 全局变量: 唯一完全的全局变量将越来越多地来自语言本身。 其他的一切都将来自模块(包括来自标准库和浏览器的功能)。
- 对检查给定标识符是否拼写正确非常有帮助(其实就是语法检查)
- ready for macros (可以使用宏了,在编译期间可操作语法树)
9.2、tree shaking使用
使用步骤:
- 定义类似如下文件
// math.js export function square { return x * x } export function cube { return x * x * x } - 在主文件中引入math.js中一个函数并使用
import {cube} from './views/math' console.log(cube(2)) - 开启 production模式这个webpack 编译标记,来自动启用 UglifyJSPlugin 压缩插件
查看处理后的代码已经删除了未用的到的代码,而且处理后的代码类似如下:
"./src/views/math.js":function(n,t,r){"use strict";function e(n){return n*n*n}r.d(t,"a",function(){return e})}});
注意:sideEffects标示出模块的哪些部分包含外部作用(side effect),也就是说标识出的这部分代码即使没有用到,也不能tree-shaking。但sideEffects在webpack的rules里及package.json里配置都没有效果???在开发环境下没有开启压缩,将函数都会打出且标记为harmony export (binding),并没有官方指南上的unused harmony export。而生产环境模式下,所有标记都会消失,且代码会压缩混淆。
通过如上方式,我们已经可以通过 import 和 export 语法,找出那些需要删除的“未使用代码(dead code)”,然而,我们不只是要找出,还需要在 bundle 中删除它们。为此,我们将使用 -p(production) 这个 webpack 编译标记,来启用 UglifyJSPlugin 插件。
再反过来看看上面官方的一段话,以及回顾一下静态数据结构,则表明,webpack可以根据import和export等语法分析出哪些代码是dead-code,然后再利用UglifyJSPlugin插件删除多余代码。
10、生产环境构建
因为生产和开发环境的构建目标差异还是很大的,在开发环境中,我们需要具有强大的、具有实时重新加载(live reloading)或热模块替换(hot module replacement)能力的 source map 和 localhost server。而在生产环境中,我们的目标则转向于关注更小的 bundle,更轻量的 source map,以及更优化的资源,以改善加载时间。 由于要遵循逻辑分离,我们通常建议为每个环境编写彼此独立的 webpack 配置。
虽然,以上我们将生产环境和开发环境做了略微区分,但是,请注意,我们还是会遵循不重复原则(Don’t repeat yourself - DRY),保留一个“通用”配置。为了将这些配置合并在一起,我们将使用一个名为 webpack-merge 的工具。通过“通用”配置,我们不必在环境特定(environment-specific)的配置中重复代码。
1、 分别将webpack配置分成如下结构,然后单独抽离各个环境下的配置
project-name
|--src
| ...
|--webpack.base.js
|--webpack.dev.js
|--webpack.prod.js
|--server.js
|--package.json
...
2、 修改package.json如下: 可以看到传参可以通过 –config xxx配置文件来实现
{
"scripts": {
"dev": "webpack-dev-server --open --config webpack.dev.js",
"server": "node server.js",
"watch": "webpack --watch",
"build": "webpack",
"dev-build": "webpack --config webpack.dev.js",
"prod-build": "webpack --config webpack.prod.js",
},
}
3、 对于压缩插件:
在webpack.prod.js里,mode为production,会自动开启UglifyJSPlugin,虽然它是代码压缩方面比较好的选择,但是还有一些其他选择:
- BabelMinifyWebpackPlugin
- ClosureCompilerPlugin 注意:如果决定尝试一些其他插件,只要确保新插件也会按照 tree shake 中所陈述的,具有删除未引用代码(dead code)的能力足矣。
4、 对于source-map 在生产环境下使用source-map,便于快速索引错误位置。在开发环境因为运行在内存中,可以使用inline-source-map。
避免在生产中使用 inline-* 和 eval-*,因为它们可以增加 bundle 大小,并降低整体性能。
5、 指定环境 许多 library 将通过与 process.env.NODE_ENV 环境变量关联,以决定 library 中应该引用哪些内容。例如,当不处于生产环境中时,某些 library 为了使调试变得容易,可能会添加额外的日志记录(log)和测试(test)。其实,当使用 process.env.NODE_ENV === ‘production’ 时,一些 library 可能针对具体用户的环境进行代码优化,从而删除或添加一些重要代码。我们可以使用 webpack 内置的 DefinePlugin 为所有的依赖定义这个变量:
const webpack = require('webpack');
const merge = require('webpack-merge');
const UglifyJSPlugin = require('uglifyjs-webpack-plugin');
const common = require('./webpack.common.js');
module.exports = merge(common, {
mode: 'production',
devtool: 'source-map',
plugins: [
new UglifyJSPlugin({
sourceMap: true
})
}),
new webpack.DefinePlugin({
'process.env.NODE_ENV': JSON.stringify('production'),
// 还可这样
'process.env': {
'NODE_ENV': JSON.stringify('production')
},
// 在生产/开发中,构建中使用不同的URL
'SERVICE_URL': JSON.stringify('https://yuccie.github.io/jsArt')
})
]
});
技术上讲,NODE_ENV 是一个由 Node.js 暴露给执行脚本的系统环境变量。通常用于决定在开发环境与生产环境(dev-vs-prod)下,服务器工具、构建脚本和客户端 library 的行为。然而,与预期不同的是,无法在构建脚本 webpack.config.js 中,将 process.env.NODE_ENV 设置为 “production”,请查看 #2537。因此,例如 process.env.NODE_ENV === ‘production’ ? ‘[name].[hash].bundle.js’ : ‘[name].bundle.js’ 这样的条件语句,在 webpack 配置文件中,无法按照预期运行。
DefinePlugin允许创建一个在编译时可以配置的全局变量。
用法:
- 如果这个值是一个字符串,它会被当作一个代码片段来使用
- 如果这个值不是字符串,它会被转化为字符串(包括函数)。
- 如果这个值是一个对象,它所有的 key 会被同样的方式定义。
- 如果在一个 key 前面加了 typeof,它会被定义为 typeof 调用。
注意:因为这个插件直接执行文本替换,给定的值必须包含字符串本身内的实际引号。通常,有两种方式来达到这个效果,使用 ‘“production”’, 或者使用 JSON.stringify(‘production’)。
11、代码分离
该特性能够把代码分离到不同的bundle中,然后可以按需加载或并行加载这些文件。代码分离可以用于获取更小的bundle,以及控制资源加载优先级,合理使用会极大影响加载时间。
三种常用的代码分离方法:
- 入口起点:使用 entry 配置手动地分离代码。
- 防止重复:使用 SplitChunks 去重和分离 chunk。
- 动态导入:通过模块的内联函数调用来分离代码。
入口起点:使用 entry 配置手动地分离代码
即将手动增加入口文件,类似如下:
entry: {
main:'./src/index.js',
other:'./src/other.js'
},
该方法的缺点:
- 如果入口chunks之间包含重复的代码,那打包之后,哪些重复的模块会被引入到各个bundle中。
- 不灵活,并且不能将核心应用程序逻辑进行动态拆分代码。
防止重复:使用 SplitChunks 去重和分离 chunk
在webpack4中使用SplitChunksPlugin插件分离代码(之前的CommonsChunkPlugin已被移除,如果在webpack4里使用会提示已移除).
The SplitChunks 插件可以将公共的依赖模块提取到已有的入口 chunk 中,或者提取到一个新生成的 chunk。
在webapck.base.js增加如下配置
// output:{},
optimization: {
splitChunks: {
chunks: 'all'
}
}
再次构建,即可看到已经将入口文件中引用的公共模块抽离出来了。。。注意,这里抽离出来的公共模块是用npm包装的,而不是自己写的模块,因为默认只分离node_modules里的文件。。。下面有具体配置
另外被抽离生成的模块名,默认命名规则为块的来源和引用文件名(例如此处的vendors~main~other.js),还需注意在开发环境若构建,引入的包即使没用,也会打包出来,因为tree shaking是配合压缩代码插件使用的。
再看下其默认配置:
// output:{},
optimization: {
splitChunks: {
//选择哪些块进行优化,值all,async,initial
// 还可以是函数,返回值将指示是否包含每个块
// 功能强大,意味着即使在异步与非异步之间也可以共享块
// 默认async是说按需加载的模块如果满足以下条件就会单独打包
chunks: 'async',
// 要生成的块的压缩前最小大小30kb,块如果太小就没必要新生成一个包
minSize: 30000,
// 分割前必须共享模块的最小块数(就是有最少多少文件公用它)
minChunks: 1,
// 按需加载时的最大并行请求数
maxAsyncRequests: 5,
// 一个入口文件中并行请求的最大数量(比如一个入口有多处按需加载的地方)
maxInitialRequests: 3,
//抽离出来的包名字分隔符
automaticNameDelimiter: '~',
// 为true则根据块及缓存组密钥生成名字。若为字符串,则就是自定义名
name: true,
// priority,一个模块可以属于多个缓存组,该优化将优先选择具有较高优先级的缓存组
// default是默认组,具有负优先级,允许自定义组具有更高优先级
cacheGroups: {
// 默认将来自node_modules的块分配到vendors缓存组里
vendors: {
// 缓存组选择哪些模块,省略它(''空字符即可)则选择所有模块。
test: /[\\/]node_modules[\\/]/,
priority: -10
},
// 所有重复引用至少两次的代码分配到default缓存组里
default: {
minChunks: 2,
priority: -20,
// boolean,如果当前块包含已经从主包中拆分出来的模块,那么它将重用,而不是新生成的模块,可能会影响块的结果文件名
reuseExistingChunk: true
}
}
}
}
注意:上面的那么多参数,其实都可以不用管,cacheGroups 才是我们配置的关键。它可以继承/覆盖上面 splitChunks 中所有的参数值,除此之外还额外提供了三个配置,分别为:test, priority 和 reuseExistingChunk。
如上面的默认配置,对于来自node_modules的模块抽离到vendors缓存组里,对于异步请求超过1次的放在default组里(默认就是async异步)。
实例一
entry: {
pageA: './src/views/pageA.js', // 引用a.js
pageB: './src/views/pageB.js', // 引用a.js 引用b.js
pageC: './src/views/pageC.js' // 引用a.js 引用b.js
}
optimization: {
splitChunks: {
chunks: 'all',
cacheGroups: {
commons: {
minSize: 0,
minChunks: 2,
}
}
}
},
如上配置,会生成commons~pageA~pageB~pageC.js,commons~pageB~pageC.js文件,因为:
- a.js
- 所有情况下的引用即all
- 引用超过1次,即3
- 生成的包大于0kb
- b.js
- 所有情况下的引用即all
- 引用超过1次,即2
- 生成的包大于0kb
注意:如果修改配置如下,则不会生成额外的包:
optimization: {
splitChunks: {
chunks: 'all',
cacheGroups: {
commons: {
// 覆盖上面的all,只能是按需加载的才满足条件
async:'async',
minSize: 0,
minChunks: 2,
}
}
}
},
因为上面是多入口,也会生成pageA.js、pageB.js、pageC.js,源文件里并没有多少代码,但生成的文件里挺大,这是因为每个生成的文件里都包含webpack运行时的一些代码,因此可以将运行时的代码再抽离出去。。。
optimization: {
splitChunks: {
// 增加下面一行即可
runtimeChunk: "single"
// 等价于下面代码
runtimeChunk: {
name: "manifest"
}
}
},
此时生成的文件会多一个runtime.js或者manifest.js
再来结合CommonsChunkPlugin理解一下,还可参考: splitChunkPluginExamples1Url
出来上面的两种分离代码插件,还有一些社区提供的,如下:
- mini-css-extract-plugin: 用于将 CSS 从主应用程序中分离。
- bundle-loader: 用于分离代码和延迟加载生成的 bundle。
- promise-loader: 类似于 bundle-loader ,但是使用的是 promises。
动态导入:通过模块的内联函数调用来分离代码
当涉及动态代码拆分时,webpack提供了两种类似的技术:
- 使用符合 ECMAScript 提案 的 import() 语法 (推荐)
- 使用 webpack 特定的 require.ensure
import() 调用会在内部用到 promises。如果在旧有版本浏览器中使用 import(),记得使用 一个 polyfill 库(例如 es6-promise 或 promise-polyfill),来 shim Promise。
以上都是静态导入某个模块,这里使用动态导入,比如动态导入lodash:
- 删除掉多余的entry及optimization.splitChunks
- 在output里增加
chunkFilename: '[name].bundle.js'- 决定非入口chunk的名称(比如抽离出来的包,如vendors~lodash.bundle.js)
- 修改index.js如下
function component() {
// import规范不允许控制模块的名称或其他属性,因为 "chunks" 只是 webpack 中的一个概念
// webpack 中可以通过注释接收一些特殊的参数,而无须破坏规定,即如下
// webpackChunkName:新 chunk 的名称,再看上面打包出来的文件名便懂
// 参考https://webpack.docschina.org/api/module-methods#import-
return import(/* webpackChunkName: "lodash" */ 'lodash').then( _ =>{
var element = document.createElement('div')
element.innerHTML = _.join(['hello', 'webpack'], ' ')
return element
}).catch((err)=>{
console.log('错误信息为:', err)
})
}
component().then( component => {
document.body.appendChild(component);
})
- 再次构建,即可看到被分离出来的
vendors~lodash.bundle.js文件
当然上面第三步的代码还可以利用async,但是需要babel和Syntax Dynamic Import Babel Plugin,如下:
async function component() {
var element = document.createElement('div')
const _ = await import(/* webpackChunkName: "lodash" */ 'lodash')
element.innerHTML = _.join(['hello', 'webpack'], ' ')
return element
}
component().then( component => {
document.body.appendChild(component);
})
Prefetching/preloading
上面我们动态导入时使用了类似import(/* webpackChunkName: "lodash" */ 'lodash')的方式,其实这里还可以使用prefetch、preload
- prefetch(在未来的某些路由页面可能需要的资源)
- 在父模块下载完成
- 浏览器空闲时下载
- 在未来的某个时候请求
- preload(在当前路由页面可能需要的资源)
- 与父模块并行下载
- 具有中等优先级并且立即下载
- 应该立即被父模块请求 使用时如
import(/* webpackPreload: true */ 'ChartingLibrary');
import(/* webpackPrefetch: true */ 'LoginModal');
这两者其实就是在最后标签里添加类似<link rel="preload">这样的效果,当然浏览器的支持度并不一致。另外尤其是preload,要注意使用,否则会损害性能。
boundle分析
如果我们以分离代码作为开始,那么就以检查模块作为结束,分析输出结果是很有用处的。
官方的分析工具
然后社区的还有
- webpack-chart: webpack 数据交互饼图
- webpack-visualizer: 可视化并分析你的 bundle,检查哪些模块占用空间,哪些可能是重复使用的。
- webpack-bundle-analyzer: 一款分析 bundle 内容的插件及 CLI 工具,以便捷的、交互式、可缩放的树状图形式展现给用户。
前三种方式都是生成一个文件webpack --profile --json > stats.json,然后通过其官网提供的接口分析即可。
webpack-bundle-analyzer需要如下:
// 首先要 npm i -D webpack-bundle-analyzer
// 然后配置webpack.base.js,运行一个构建任务即可自动打开一个页面
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
module.exports = {
plugins: [
new BundleAnalyzerPlugin()
]
}
12、懒加载
懒加载或者按需加载,是先把代码在一些逻辑点处分离开,然后在一些代码块中完成某些操作,立即引用或即将引用另外一些新的代码块。
因为之前做代码分离,虽然分离了代码块lodash.bundle.js ,但这个包每次加载页面的时候都会请求,这会对性能造成负面影响,因此可以懒加载它,即当用户操作某一逻辑后,才去加载它。 1、新建与index.js同级的print.js,如:
console.log('The print.js module has loaded! See the network tab in dev tools...');
export default () => {
console.log('Button Clicked: Here\'s "some text"!');
}
2、修改index.js,如下:
import _ from 'lodash'
function component(){
var ele = document.createElement('div')
var btn = document.createElement('button')
var br = document.createElement('br')
btn.innerHTML = 'Click me and look at the console!'
ele.appendChild(br)
ele.appendChild(btn)
btn.onclick = e => import(/* webpackChunkName: 'print' */ './print').then(module => {
var print = module.default
print()
})
return ele
}
document.body.appendChild(component())
3、启动服务或构建完打开index.html即可 打开控制台,可以看到print.bundle.js文件页面初始化时并没有加载,而是在单击按钮之后才发起了请求
注意当调用 ES6 模块的 import() 方法(引入模块)时,必须指向模块的 .default 值,因为它才是 promise 被处理后返回的实际的 module 对象。
许多框架和类库对于如何用它们自己的方式来实现(懒加载)都有自己的建议。这里有一些例子:
更多懒加载参考:es5模块化在浏览器里的懒加载
13、缓存
以上通过webpack构建生成dist目录,只要这个目录部署到服务器上,客户端(通常是浏览器)就能够访问网站此服务器的网站及其资源,而这一步很耗时间,这就是为什么浏览器使用一种名为缓存的技术。可以通过命中缓存,以降低网络流量,使网站加载速度更快。。。
然而,如果我们在部署新版本时不更改资源的文件名,浏览器会认为它没有被更新,就会使用它的缓存版本。由于需要获取新的代码时,就会显得很棘手。
当我们修改output的filename为[name].[contenthash].js后,在文件不改动的情况下,反复构建按道理说文件名是不会再变的。。。但并不一定。。。这是因为:
This is because webpack includes certain boilerplate, specifically the runtime and manifest, in the entry chunk. 这是因为 webpack 包含某些模板,特别是运行时和manifest清单,在入口模块中
既然,运行时或者manifest清单会导致构建后文件名发生变化,那如果给它单独抽离出来不就好了。。。那什么是运行时和manifest呢,其实就是在浏览器运行时,webpack用来连接模块化的应用程序的所有代码
runtime:在模块交互时,连接模块所需的加载和解析逻辑。包括浏览器中的已加载模块的连接,以及懒加载模块的执行逻辑。
manifest:
那么,一旦你的应用程序中,形如 index.html 文件、一些 bundle 和各种资源加载到浏览器中,会发生什么?你精心安排的 /src 目录的文件结构现在已经不存在,所以 webpack 如何管理所有模块之间的交互呢?这就是 manifest 数据用途的由来……
当编译器(compiler)开始执行、解析和映射应用程序时,它会保留所有模块的详细要点。这个数据集合称为 “Manifest”,当完成打包并发送到浏览器时,会在运行时通过 Manifest 来解析和加载模块。无论你选择哪种模块语法,那些 import 或 require 语句现在都已经转换为 webpack_require 方法,此方法指向模块标识符(module identifier)。通过使用 manifest 中的数据,runtime 将能够查询模块标识符,检索出背后对应的模块。
比如懒加载一个模块,如果单纯修改这个模块,并将运行时抽离出去之后,是不会影响到主文件,此时只会改变该模块和抽离出去的manifest文件(或runtime.js文件),另外就是可以在manifest文件里索引到该模块的hash值,如下看f8def119字段:
// manifest.69245d81.js
/******/ // script path function
/******/ function jsonpScriptSrc(chunkId) {
/******/ return __webpack_require__.p + "" + ({"print":"print"}[chunkId]||chunkId) + "." + {"print":"f8def119"}[chunkId] + ".bundle.js"
/******/ }
// 文件名
// print.f8def119.bundle.js
Extracting Boilerplate提取模板
使用SplitChunkPlugin可以被用来将模块分割成不同的包,webpack提供一个优化特性,可以根据提供的选项将运行时代码分割成一个独立的块。只需如下:
output: {},
optimization: {
runtimeChunk: 'single'
}
这样的结果是在单独的把运行时相关的代码抽离出来形成一个包。再修改单独的文件,就不会影响到主文件了。
提取第三方库
提取第三方库其实就是上面说的SplitChunks,参考上文。
module indentifiers 模块标识符
有时候我们会只修改一个主文件,但是重新打包会引起之前打包出来的第三方包的文件名也发生变化。。。其实这主要是因为:因为每个 module.id 都是基于默认的解析顺序进行递增的。 意思是当解析的顺序被改变时,id 也会被改变。
因此可以通过以下两种插件来修复:
- NamedModulesPlugin(开发环境易读,生产环境则耗时很多)
- HashedModuleIdsPlugin(推荐用于生产)
webapck暂时告一段落,这篇文章涉及了很多技术点,有些技术点只是大概说说原理,如需更深入,则需要查看相关连接。。。随着技术栈理解的越来越深,上面的还会再变动,因此只做参考。。。
待整理:
- sass,less,css等文件的统一性处理
- webapck4框架学习
14、scss & sass
注意 sass-loader 会默认处理不基于缩进的 scss 语法。为了使用基于缩进的 sass 语法,你需要向这个 loader 传递选项:
{
test: /\.sass$/,
use: [
'vue-style-loader',
'css-loader',
{
loader: 'sass-loader',
options: {
indentedSyntax: true
}
}
]
}
webpack解说版本二
参考:webpack原理
流程概括
Webpack 的运行流程是一个串行的过程,从启动到结束会依次执行以下流程:
- 初始化参数:从配置文件和 Shell 语句中读取与合并参数,得出最终的参数;
- 开始编译:用上一步得到的参数初始化 Compiler 对象,加载所有配置的插件,执行对象的 run 方法开始执行编译;
- 确定入口:根据配置中的 entry 找出所有的入口文件;
- 编译模块:从入口文件出发,调用所有配置的 Loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理;
- 完成模块编译:在经过第4步使用 Loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系;
- 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会;
- 输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
在以上过程中,Webpack 会在特定的时间点广播出特定的事件,插件在监听到感兴趣的事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果。
流程细节
// Webpack 的构建流程可以分为以下三大阶段(初始化 -> 编译 -> 输出):
// 1. 初始化:启动构建,读取与合并配置参数,加载 Plugin,实例化 Compiler。
// 2. 编译:从 Entry 发出,针对每个 Module 串行调用对应的 Loader 去翻译文件内容,再找到该 Module 依赖的 Module,递归地进行编译处理。
// 3. 输出:对编译后的 Module 组合成 Chunk,把 Chunk 转换成文件,输出到文件系统。
// 在每个阶段都会发生很多事件,webpack会把这些事件广播出来供plugin使用。
// 过程一:初始化阶段
// 1. 初始化参数,从配置文件和 Shell 语句中读取与合并参数,得出最终的参数。 这个过程中还会执行配置文件中的插件实例化语句 new Plugin()。
// 2. 实例化compiler,用上一步得到的参数初始化 Compiler 实例,Compiler 负责文件监听和启动编译。Compiler 实例中包含了完整的 Webpack 配置,全局只有一个 Compiler 实例。
// 3. 加载插件,依次调用插件的 apply 方法,让插件可以监听后续的所有事件节点。同时给插件传入 compiler 实例的引用,以方便插件通过 compiler 调用 Webpack 提供的 API。
// 4. environment,开始应用 Node.js 风格的文件系统到 compiler 对象,以方便后续的文件寻找和读取。
// 5. entry-option,读取配置的Entrys,为每个 Entry 实例化一个对应的 EntryPlugin,为后面该 Entry 的递归解析工作做准备。
// 6. after-plugins,调用完所有内置的和配置的插件的 apply 方法。
// 7. after-resolvers,根据配置初始化完 resolver,resolver 负责在文件系统中寻找指定路径的文件。
// 过程二:编译阶段
// 1. run,启动一次新的编译
// 2. watch-run,和 run 类似,区别在于它是在监听模式下启动的编译,在这个事件中可以获取到是哪些文件发生了变化导致重新启动一次新的编译。
// 3. compile,该事件是为了告诉插件一次新的编译将要启动,同时会给插件带上 compiler 对象。
// 4. compilation,当 Webpack 以开发模式运行时,每当检测到文件变化,一次新的 Compilation 将被创建。一个 Compilation 对象包含了当前的模块资源、编译生成资源、变化的文件等。Compilation 对象也提供了很多事件回调供插件做扩展。
// 5. make,一个新的 Compilation 创建完毕,即将从 Entry 开始读取文件,根据文件类型和配置的 Loader 对文件进行编译,编译完后再找出该文件依赖的文件,递归的编译和解析。
// 6. after-compile,一次 Compilation 执行完成。
// 7. invalid,当遇到文件不存在、文件编译错误等异常时会触发该事件,该事件不会导致 Webpack 退出。
// 注意:编译阶段中,最重要的要数 compilation 事件了,
// 因为在 compilation 阶段调用了 Loader 完成了每个模块的转换操作,
// 在 compilation 阶段又包括很多小的事件,它们分别是:
// 1. build-module,使用对应的 Loader 去转换一个模块。
// 2. normal-module-loader,在用 Loader 对一个模块转换完后,使用 acorn 解析转换后的内容,输出对应的抽象语法树(AST),以方便 Webpack 后面对代码的分析。
// 3. program,从配置的入口模块开始,分析其 AST,当遇到 require 等导入其它模块语句时,便将其加入到依赖的模块列表,同时对新找出的依赖模块递归分析,最终搞清所有模块的依赖关系。
// 4. seal,所有模块及其依赖的模块都通过 Loader 转换完成后,根据依赖关系开始生成 Chunk。
// 过程三:输出阶段
// 1. should-emit,所有需要输出的文件已经生成好,询问插件哪些文件需要输出,哪些不需要。
// 2. emit,确定好要输出哪些文件后,执行文件输出,可以在这里获取和修改输出内容。
// 3. after-emit,文件输出完毕
// 4. done,成功完成一次完成的编译和输出流程。
// 5. failed,如果在编译和输出流程中遇到异常导致 Webpack 退出时,就会直接跳转到本步骤,插件可以在本事件中获取到具体的错误原因。
// 在输出阶段已经得到了各个模块经过转换后的结果和其依赖关系,并且把相关模块组合在一起形成一个个 Chunk。
// 在输出阶段会根据 Chunk 的类型,使用对应的模版生成最终要要输出的文件内容。
// 输出代码分析
// 为什么bundle.js能直接运行在浏览器中?
// 答:原因在于输出的文件中通过 __webpack_require__ 函数定义了一个可以在浏览器中执行的加载函数来模拟 Node.js 中的 require 语句。
// 为何将很多模块放在一个bundle.js里?
// 答:原因在于浏览器不能像 Node.js 那样快速地去本地加载一个个模块文件,而必须通过网络请求去加载还未得到的文件。 如果模块数量很多,加载时间会很长,因此把所有模块都存放在了数组中,执行一次网络加载。
// __webpack_require__ 函数有优化,加载过的模块不会二次加载。
// 分隔代码的输出
// 异步加载 show.js
import('./show').then((show) => {
// 执行 show 函数
show('Webpack');
});
// 上面代码构建后,会输出两个文件,分别是执行入口文件 bundle.js 和 异步加载文件 0.bundle.js。
// 其中 0.bundle.js的内容如下:
webpackJsonp(
// 在其它文件中存放着的模块的 ID
[0],
// 本文件所包含的模块
[
// show.js 所对应的模块
(function (module, exports) {
function show(content) {
window.document.getElementById('app').innerText = 'Hello,' + content;
}
module.exports = show;
})
]
);
// 1. __webpack_require__.e 用于加载被分割出去的,需要异步加载的 Chunk 对应的文件;
// 2. webpackJsonp 函数用于从异步加载的文件中安装模块。
// 在使用了 CommonsChunkPlugin 去提取公共代码时输出的文件和使用了异步加载时输出的文件是一样的,
// 都会有 __webpack_require__.e 和 webpackJsonp。 原因在于提取公共代码和异步加载本质上都是代码分割。
// loader基础
// 由于 Webpack 是运行在 Node.js 之上的,一个 Loader 其实就是一个 Node.js 模块,这个模块需要导出一个函数。
// 这个导出的函数的工作就是获得处理前的原内容,对原内容执行处理后,返回处理后的内容。
// 一个最简单的 Loader 的源码如下:
module.exports = function(source) {
// source 为 compiler 传递给 Loader 的一个文件的原内容
// 该函数需要返回处理后的内容,这里简单起见,直接把原内容返回了,相当于该 Loader 没有做任何转换
return source;
};
// 由于 Loader 运行在 Node.js 中,你可以调用任何 Node.js 自带的 API,或者安装第三方模块进行调用:
const sass = require('node-sass');
module.exports = function(source) {
return sass(source);
};
// loader进阶
// Webpack 还提供一些 API 供 Loader 调用
// 可以获取Loader的options
// 还可以返回其他的数据,比如sourceMap
// loader有同步和异步之分,有些需要通过网络请求,才能得到结果,同步则会阻塞整个构建,导致构建非常缓慢。
// 在转换步骤是异步时,可以:
module.exports = function(source) {
// 告诉 Webpack 本次转换是异步的,Loader 会在 callback 中回调结果
var callback = this.async();
someAsyncOperation(source, function(err, result, sourceMaps, ast) {
// 通过 callback 返回异步执行后的结果
callback(err, result, sourceMaps, ast);
});
};
// 处理二进制数据
// 在默认的情况下,Webpack 传给 Loader 的原内容都是 UTF-8 格式编码的字符串。 但有些场景下 Loader 不是处理文本文件,而是处理二进制文件,
// 例如 file-loader,就需要 Webpack 给 Loader 传入二进制格式的数据。 为此,你需要这样编写 Loader:
module.exports = function(source) {
// 在 exports.raw === true 时,Webpack 传给 Loader 的 source 是 Buffer 类型的
source instanceof Buffer === true;
// Loader 返回的类型也可以是 Buffer 类型的
// 在 exports.raw !== true 时,Loader 也可以返回 Buffer 类型的结果
return source;
};
// 通过 exports.raw 属性告诉 Webpack 该 Loader 是否需要二进制数据
module.exports.raw = true;
// 缓存加速
// 有些转换操作需要大量计算非常耗时,如果每次构建都重新执行重复的转换操作,构建将会变得非常缓慢。
// Webpack 会默认缓存所有 Loader 的处理结果,也就是说在需要被处理的文件或者其依赖的文件没有发生变化时, 是不会重新调用对应的 Loader 去执行转换操作的。
module.exports = function(source) {
// 关闭该 Loader 的缓存功能
this.cacheable(false);
return source;
};
// ResolveLoader
// ResolveLoader 用于配置 Webpack 如何寻找 Loader。 默认情况下只会去 node_modules 目录下寻找,
// 为了让 Webpack 加载放在本地项目中的 Loader 需要修改 resolveLoader.modules。
// 假如本地的 Loader 在项目目录中的 ./loaders/loader-name 中,则需要如下配置:
module.exports = {
resolveLoader:{
// 去哪些目录下寻找 Loader,有先后顺序之分
modules: ['node_modules','./loaders/'],
}
}
// 加上以上配置后, Webpack 会先去 node_modules 项目下寻找 Loader,如果找不到,会再去 ./loaders/ 目录下寻找。
开发一个插件
该插件的名称取名叫 EndWebpackPlugin,作用是在 Webpack 即将退出时再附加一些额外的操作,例如在 Webpack 成功编译和输出了文件后执行发布操作把输出的文件上传到服务器。 同时该插件还能区分 Webpack 构建是否执行成功。使用该插件时方法如下:
module.exports = {
plugins:[
// 两个参数分别为成功回调和失败回调。
new EndWebpackPlugin(() => {
// Webpack 构建成功,并且文件输出以后会执行到这里,在这里可以做发布文件操作
}, (err) => {
console.error(err);
})
]
}
// 要实现该插件,需要借助两个事件:
// 1. done:在成功构建并且输出了文件后,Webpack 即将退出时发生;
// 2. failed:在构建出现异常导致构建失败,Webpack 即将退出时发生;
class EndWebpackPlugin {
constructor(doneCb, failCb){
// 存在在构造函数中传入的回调函数
this.doneCallback = doneCb;
this.failCallback = failCb;
}
apply(compailer){
compailer.plugin('done', (stats) => {
// 在done事件中回调doneCallback
this.doneCallback(stats);
});
compailer.plugin('failed', (err) => {
this.failCallback(err);
})
}
}
module.exports = EndWebpackPlugin
// 调用过程
// 1. Webpack 启动后,在读取配置的过程中会先执行 new EndWebpackPlugin(options) 初始化一个 EndWebpackPlugin 获得其实例。
// 2. 在初始化 compiler 对象后,再调用 EndWebpackPlugin.apply(compiler) 给插件实例传入 compiler 对象。
// 3. 插件实例在获取到 compiler 对象后,就可以通过 compiler.plugin(事件名称, 回调函数) 监听到 Webpack 广播出来的事件。
// 4. 并且可以通过 compiler 对象去操作 Webpack。
常见细节:
// Compiler 和 Compilation
// 1. Compiler 对象包含了 Webpack 环境所有的的配置信息,包含 options,loaders,plugins 这些信息,
// 这个对象在 Webpack 启动时候被实例化,它是全局唯一的,可以简单地把它理解为 Webpack 实例;
// 2. Compilation 对象包含了当前的模块资源、编译生成资源、变化的文件等。当 Webpack 以开发模式运行时,每当检测到一个文件变化,一次新的 Compilation 将被创建。
// Compilation 对象也提供了很多事件回调供插件做扩展。通过 Compilation 也能读取到 Compiler 对象。
// Compiler 和 Compilation 的区别在于:
// Compiler 代表了整个 Webpack 从启动到关闭的生命周期,而 Compilation 只是代表了一次新的编译。
// Webpack 的事件流机制应用了观察者模式,和 Node.js 中的 EventEmitter 非常相似。
// 可以直接在 Compiler 和 Compilation 对象上广播和监听事件,方法如下:
/**
* 广播出事件
* event-name 为事件名称,注意不要和现有的事件重名
* params 为附带的参数
*/
compiler.apply('event-name',params);
/**
* 监听名称为 event-name 的事件,当 event-name 事件发生时,函数就会被执行。
* 同时函数中的 params 参数为广播事件时附带的参数。
*/
compiler.plugin('event-name',function(params) {
// todo
});
// 监听文件变化
// Webpack 会从配置的入口模块出发,依次找出所有的依赖模块,当入口模块或者其依赖的模块发生变化时, 就会触发一次新的 Compilation。
// 默认情况下 Webpack 只会监视入口和其依赖的模块是否发生变化,在有些情况下项目可能需要引入新的文件,例如引入一个 HTML 文件。
// 由于 JavaScript 文件不会去导入 HTML 文件,Webpack 就不会监听 HTML 文件的变化,编辑 HTML 文件时就不会重新触发新的 Compilation。
// 为了监听 HTML 文件的变化,我们需要把 HTML 文件加入到依赖列表中,为此可以使用如下代码:
compiler.plugin('after-compile', (compilation, callback) => {
// 把 HTML 文件添加到文件依赖列表,好让 Webpack 去监听 HTML 模块文件,在 HTML 模版文件发生变化时重新启动一次编译
compilation.fileDependencies.push(filePath);
callback();
});
// 修改输出资源
// 有些场景下插件需要修改、增加、删除输出的资源,要做到这点需要监听 emit 事件,
// 因为发生 emit 事件时所有模块的转换和代码块对应的文件已经生成好,需要输出的资源即将输出,
// 因此 emit 事件是修改 Webpack 输出资源的最后时机。
// 所有需要输出的资源会存放在 compilation.assets 中,compilation.assets 是一个键值对,键为需要输出的文件名称,值为文件对应的内容。
compiler.plugin('emit', (compilation, callback) => {
// 设置名称为 fileName 的输出资源
compilation.assets[fileName] = {
// 返回文件内容
source: () => {
// fileContent 既可以是代表文本文件的字符串,也可以是代表二进制文件的 Buffer
return fileContent;
},
// 返回文件大小
size: () => {
return Buffer.byteLength(fileContent, 'utf8');
}
};
callback();
});
// 读取 compilation.assets 的代码如下:
compiler.plugin('emit', (compilation, callback) => {
// 读取名称为 fileName 的输出资源
const asset = compilation.assets[fileName];
// 获取输出资源的内容
asset.source();
// 获取输出资源的文件大小
asset.size();
callback();
});
// 还可以判断webpack安装哪些插件,无非也就是利用compiler对象
// 判断当前配置是否使用了 ExtractTextPlugin?
// compiler 参数即为 Webpack 在 apply(compiler) 中传入的参数
function hasExtractTextPlugin(compiler) {
// 当前配置所有使用的插件列表
const plugins = compiler.options.plugins;
// 去 plugins 中寻找有没有 ExtractTextPlugin 的实例
return plugins.find(plugin=>plugin.__proto__.constructor === ExtractTextPlugin) != null;
}
vue-loader
参考:vue-loader参考官方文档(old)、vue-loader官方文档(new)、
CSS Modules
CSS Modules是一个用于模块化和组合 CSS 的流行系统。vue-loader 提供了与 CSS 模块的一流集成,可以作为模拟 CSS 作用域的替代方案。
/* 在 .vue 中你可以定义不止一个 <style>,为了避免被覆盖,你可以通过设置 module 属性来为它们定义注入后计算属性的名称。如:module="a" ,用的时候直接a.red即可*/
<style module>
.red {
color: red;
}
.bold {
font-weight: bold;
}
</style>
<template>
<p :class="$style.red">
This should be red
</p>
</template>
<!-- 由于它是一个计算属性,它也适用于 :class 的 object/array 语法: -->
<template>
<div>
<!-- 需要Bublé编译器,而非babel -->
<!-- {[$style.red]: isRed} 等价于 { isRed?[$style.red]:null } -->
<p :class="{ [$style.red]: isRed }">
Am I red?
</p>
<p :class="[$style.red, $style.bold]">
Red and bold
</p>
</div>
</template>
热重载
“热重载”不是当你修改文件的时候简单重新加载页面。启用热重载后,当你修改 .vue 文件时,所有该组件的实例会被替换,并且不需要刷新页面。它甚至保持应用程序和被替换组件的当前状态!当你调整模版或者修改样式时,这极大的提高了开发体验。
-
当编辑一个组件的
<template>时,这个组件实例将就地重新渲染,并保留当前所有的私有状态。能够做到这一点是因为模板被编译成了新的无副作用的渲染函数。 -
当编辑一个组件的
<script>时,这个组件实例将就地销毁并重新创建。(应用中其它组件的状态将会被保留) 是因为<script>可能包含带有副作用的生命周期钩子,所以将重新渲染替换为重新加载是必须的,这样做可以确保组件行为的一致性。这也意味着,如果你的组件带有全局副作用,则整个页面将会被重新加载。 -
<style>会通过vue-style-loader自行热重载,所以它不会影响应用的状态。
使用预处理器
在 webpack 中,所有的预处理器需要匹配对应的 loader。vue-loader 允许你使用其它 webpack loader 处理 Vue 组件的某一部分。它会根据 lang 属性自动推断出要使用的 loader。
<style lang="sass">
/* write sass here */
</style>
在内部,<style> 标签中的内容将会先由 sass-loader 进行处理,然后再传递进行下一步处理。
资源路径处理
默认情况下,vue-loader 使用 css-loader 和 Vue 模版编译器自动处理样式和模版文件。在编译过程中,所有的资源路径例如 <img src="...">、background: url(...)和 @import 会作为模块依赖。
- 如果路径是绝对路径,会原样保留。
- 如果路径以 . 开头,将会被看作相对的模块依赖,并按照你的本地文件系统上的目录结构进行解析。
- 如果路径以 ~ 开头,其后的部分将会被看作模块依赖。这意味着你可以用该特性来引用一个 node 依赖中的资源:
- (13.7.0+) 如果路径以 @ 开头,也会被看作模块依赖。如果你的 webpack 配置中给 @ 配置了 alias,这就很有用了。所有 vue-cli 创建的项目都默认配置了将 @ 指向 /src。
提取vue中css
var ExtractTextPlugin = require("extract-text-webpack-plugin")
module.exports = {
// other options...
module: {
rules: [
{
test: /\.vue$/,
loader: 'vue-loader',
options: {
extractCSS: true
}
}
]
},
plugins: [
new ExtractTextPlugin("style.css")
]
}
注意:上述内容将自动处理 *.vue 文件内的 <style> 提取,并与大多数预处理器一样开箱即用。注意这只是提取 *.vue 文件 - 但在 JavaScript中导入的 CSS 仍然需要单独配置。
cssloader统一处理
cli之utils分析(简书)、cli之utils分析(博客)
postcss是什么鬼
其实postcss就是一个平台,在平台上可以借助各种中间件,实现各种操作,如下是自动添加前缀的中间件。
// 先安装postcss,autoprefixer,然后node运行这个文件
var postcss = require('postcss');
var autoprefixer = require('autoprefixer');
var fs = require('fs');
var css = '* { transition: all .1s; }';
postcss([autoprefixer])
.process(css)
.then(function(result) {
// 这一行是学习的时候需要的,看一下到底对象里面包含什么
console.log(result);
if (result.css) {
fs.writeFileSync('index.css', result.css);
}
if (result.map) {
fs.writeFileSync('index.css.map', result.map);
}
});
# 还可以直接命令行模式运行,用autoprefixer中间件添加浏览器前缀
postcss index.css -u autoprefixer -r -o index.css
autoprefixer之Browserslist
autoprofixer使用的browserslist,也就是说autoprefixer自动添加前缀插件是根据浏览器来的,如果当前浏览器支持某条css命令,则默认是不添加的。因此如果browserlist浏览器列表设置的都是高版本浏览器,则可能webpack构建出来的文件是不带css前缀的。。。
还有一种解决方法:OptimizeCSSPlugin关闭autoprefixer,但是这种方法是将所有浏览器都添加前缀,不太友好,更好的方式是自动判断哪些浏览器需要才添加。
而配置browserslist最好的方式是新建.browserslistrc在根目录,或者在package.json文件里添加browserslist字段。这样的配置还可以与babel-preset-env 、Stylelint共享。
注意:vue-loader 15之前的版本,会默认对.vue文件里的css应用PostCSS,也就是即使在.vue文件里不应用autoprefixer也会自动添加前缀。
可以根据不同browser参数来查看都有哪些浏览器:测试不同参数下的浏览器。
要测试某些属性在当前浏览器是否支持,可以查看canIUse
- 红色,表示不支持
- 黄色,表示部分支持或者需要添加前缀
- 绿色,表示已成为标准,可以直接使用
postcss-cssnext
cssnext是下一代css插件,但与css4并不是一回事。另外就是如果用postcss-cssnext插件,则就不需要用autoprefixer了,因为已经内置在前者中了。
// .postcssrc.js
module.exports = {
"plugins": {
"postcss-import": {},
"postcss-url": {},
// to edit target browsers: use "browserslist" field in package.json
// browserslist: {},
// cssnext下一代css语法,内部包含了autoprefixer,再次声明则会有警告
"postcss-cssnext": {},
// "autoprefixer": {}
}
}