写在前面:平时开发中总是遇见相同的问题,但很多时候都需要重新查找相关资料才可以,不但浪费了时间,而且每次都有种重新开始的感觉。。。因此将这些常见问题总结在一起,后续再有相关问题,都将其归为一类进行总结对比学习。
参考资料
参考 js 秘密花园、JavaScript 高级程序设计、你不知道的 JavaScript 系列、
javascript 的前世今生
基本概念
严格模式
ECMAScript 5 引入严格模式的概念,是为 javascript 定义了一种不同的解析与执行模型。在严格模式下,ECMAScript 3 中不确定的行为或某些不安全的操作都做了一些限制或错误处理。要在整个脚本启用严格模式,可以在顶部添加:use strict
这段代码看似为字符串,而且也没有赋值给任何变量,但其实是一个编译指示(pragma),用来告诉支持的 js 引擎切换到严格模式。这是为了不破坏 ECMAScript 3 语法而特意选定的语法,还可以在指定函数为严格模式:
function doSomething() {
"use strict";
// TODO
}
自动分号
语句的分号不是必须的,但建议任何时候都加上。因为:
- 避免不必要的错误(不完整输入)
- 代码结尾处没有分号会导致压缩错误
- 加上分号某些情况下会增进代码性能(解析器不必再花时间推测哪里插入分号)
代码块 {}
可以借鉴 c 风格的语法把多条语句组合在一个代码块里,虽然 if 语句只在执行多条语句时,才要求使用代码块,但最佳实践是始终使用代码块,即使只有一条语句,如:
if (test) console.log("test"); // 有效但容易出错,不要使用
if (test) {
console.log("test"); // 推荐
}
let 关键字可以将变量绑定到所在的任意作用域中(通常是{ .. }内部)。换句话说,let为其声明的变量隐式地了所在的块作用域。
var foo = true;
if (foo) {
let bar = foo * 2;
console.log(bar); // 2
}
console.log(bar); // ReferenceError
用 let 将变量附加在一个已经存在的块作用域上的行为是隐式的。在开发和修改代码的过程中,如果没有密切关注哪些块作用域中有绑定的变量,并且习惯性地移动这些块或者将其包含在其他的块中,就会导致代码变得混乱。
为块作用域显式地创建块可以部分解决这个问题,使变量的附属关系变得更加清晰。通常来讲,显式的代码优于隐式或一些精巧但不清晰的代码。显式的块作用域风格非常容易书写,并且和其他语言中块作用域的工作原理一致:
var foo = true;
if (foo) {
{
// <-- 显式的块
let bar = foo * 2;
console.log(bar); // 2
}
}
console.log(bar); // ReferenceError
只要声明是有效的,在声明中的任意位置都可以使用{ .. }括号来为let 创建一个用于绑定的块。在这个例子中,我们在 if 声明内部显式地创建了一个块,如果需要对其进行重构,整个块都可以被方便地移动而不会对外部 if 声明的位置和语义产生任何影响。
提升是指声明会被视为存在于其所出现的作用域的整个范围内,但是,使用let进行的声明不会提升。
块作用域对垃圾收集及let循环有很大帮助,
function process(data) {
// 在这里做点有趣的事情
}
var someReallyBigData = { .. };
process( someReallyBigData );
var btn = document.getElementById( "my_button" );
btn.addEventListener( "click", function click(evt) {
console.log("button clicked");
}, /*capturingPhase=*/false );
click函数的点击回调并不需要someReallyBigData 变量。理论上这意味着当process(..)执行后,在内存中占用大量空间的数据结构就可以被垃圾回收了。但是,由于 click 函数形成了一个覆盖整个作用域的闭包,JavaScript引擎极有可能依然保存着这个结构(取决于具体
实现)。因此如果块作用域可以打消这种顾虑,可以让引擎清楚的知道没有必要继续保存someReallyBigData了:
// 在这个块中定义的内容可以销毁了!
{
let someReallyBigData = { .. };
process( someReallyBigData );
}
.let循环
for 循环头部的 let 不仅将 i 绑定到了 for 循环的块中,事实上它将其重新绑定到了循环的每一个迭代中,确保使用上一个循环迭代结束时的值重新进行赋值。下面通过另一种方式来说明每次迭代时进行重新绑定的行为:
{
let j;
for (j = 0; j < 5; j++) {
let i = j; // 每个迭代重新绑定!
console.log(i); // 0 1 2 3 4
}
}
注意:let声明附属于一个新的作用域而不是当前的函数作用域(也不属于全局作用域),函数不是唯一的作用域单元。块作用域指的是变量和函数不仅可以属于所处的作用域,也可以属于某个代码块(通常指{ .. } 内部)。
作用域提升
引擎会在解释JavaScript代码之前首先对其进行编译。编译阶段中的一部分工作就是找到所有的声明,并用合适的作用域将它们关联起来。
因此,正确的思考思路是,包括变量和函数在内的所有声明都会在任何代码被执行前首先被处理。
console.log(a); // undefined
var a = 2;
当你看到var a = 2;时,可能会认为这是一个声明。但JavaScript 实际上会将其看成两个声明:var a; 和a = 2;。第一个定义声明是在编译阶段进行的。第二个赋值声明会被留在原地等待执行阶段。也就是处理成如下:
var a;
a = 2;
console.log(a); // undefined
注意:提升是针对所有代码,即使是函数内部的声明也会提升,只是函数内的提升只能提升到函数内的最顶层。另外只有函数声明会提升,但函数表达式不会提升
foo(); // 不是ReferenceError, 而是TypeError!
var foo = function bar() {
// ...
};
这段程序中的变量标识符foo被提升并分配给所在作用域(在这里是全局作用域),因此foo()不会导致ReferenceError。但是foo此时并没有赋值(如果它是一个函数声明而不是函数表达式,那么就会赋值)。foo()由于对undefined值进行函数调用而导致非法操作,因此抛出 TypeError 异常。
注意:函数声明和变量声明都会被提升。但是一个值得注意的细节(这个细节可以出现在有多个“重复”声明的代码中)是函数会首先被提升,然后才是变量。也就是函数会覆盖变量。
闭包
function wait(message) {
setTimeout(function timer() {
console.log(message);
}, 1000);
}
wait("Hello, closure!");
将一个内部函数(名为timer)传递给setTimeout(..)。timer 具有涵盖wait(..) 作用域的闭包,因此还保有对变量message 的引用。wait(..) 执行 1000 毫秒后,它的内部作用域并不会消失,timer 函数依然保有wait(..)作用域的闭包。
var a = 2;
(function IIFE() {
console.log(a); // 2
})();
严格来说,上面的代码并不是闭包,因为函数(IIFE)并不是在它本身的词法作用域以外执行的。更多的是通过普通的词法作用域查找而非闭包。。。
尽管IIFE本身并不是观察闭包最好的例子,但却和闭包息息相关,看下面循环:
for (var i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i);
}, i * 1000);
}
上面的代码只会打印 5 个 6,而不是想象中 1、2、…,缺陷是我们试图假设循环中的每个迭代在运行时都会给自己“捕获”一个 i 的副本。但是根据作用域的工作原理,实际情况是尽管循环中的五个函数是在各个迭代中分别定义的,但是它们都被封闭在一个共享的全局作用域中,因此实际上只有一个 i。
缺陷是什么?我们需要更多的闭包作用域,特别是在循环的过程中每个迭 代都需要一个闭包作用域。
// 但是这样依然不行,因此每个作用域是空的,
for (var i = 1; i <= 5; i++) {
(function() {
setTimeout(function timer() {
console.log(i);
}, i * 1000);
})();
}
// 下面的便可以,因此每次都封装一个j
for (var i = 1; i <= 5; i++) {
(function() {
var j = i;
setTimeout(function timer() {
console.log(j);
}, j * 1000);
})();
}
// 改进一下,通过给IIFE传参
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(function timer() {
console.log(j);
}, j * 1000);
})(i);
}
在迭代内使用 IIFE 会为每个迭代都生成一个新的作用域,使得延迟函数的回调可以将新的作用域封闭在每个迭代内部,每个迭代中都会含有一个具有正确值的变量供我们访问。
使用IIFE在每次迭代时。都创建一个新的作用域,换句话说,每次迭代我们都需要一个块作用域。。。而let就是用来劫持块作用域,并且在这个块作用域中声明一个变量。
// 如下便是利用let来劫持块作用域
for (var i = 1; i <= 5; i++) {
let j = i; // 是的,闭包的块作用域!
setTimeout(function timer() {
console.log(j);
}, j * 1000);
}
但是,这还不是全部!,for 循环头部的 let 声明还会有一个特殊的行为。这个行为指出变量在循环过程中不止被声明一次,每次迭代都会声明。随后的每个迭代都会使用上一个迭代结束时的值来初始化这个变量。
// 此处let声明的i每次都会声明,而且每次都会用上一次迭代结束时的值初始化
for (let i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i); // 1 2 3 4 5
}, i * 1000);
}
变量
ECMAScript 的变量是松散型的,也就是可以保存任何类型的数据。换句话说,每个变量仅仅是一个用于保存值得占位符而已,定义变量时,要使用var,let,const等操作符(同时也是关键字),后跟变量名(即标识符)
var msg;
上面代码定义了一个名为msg的变量,可以用来保存任何值(上面那样未经初始化的变量,会保存一个特殊的值undefined)。
var msg = "hi javascript";
msg = 100; // 有效但不推荐
像上面那样先初始化一个字符串数据类型,后又改为数字类型,这种即改变变量值又改变值类型的行为不推荐。
。所有变量(包括基本类型和引用类型)都存在与一个执行环境(也叫作用域)中,这个执行环境决定了变量的生命周期,以及哪一部分代码可以访问其中的变量。
this,bind,call,apply
它是一个很特别的关键字,被自动定义在所有函数的作用域中,那我们为甚么要使用this呢?
function identify() {
return this.name.toUpperCase();
}
function speak() {
var greeting = "Hello, I'm " + identify.call(this);
console.log(greeting);
}
var me = {
name: "Kyle"
};
var you = {
name: "Reader"
};
identify.call(me); // KYLE
identify.call(you); // READER
speak.call(me); // Hello, 我是KYLE
speak.call(you); // Hello, 我是 READER
// 这段代码可以在不同的上下文对象(me 和you)中重复使用函数identify() 和speak(),
// 不用针对每个对象编写不同版本的函数。
// 其实根据最佳实践来说,共享函数都是定义在原型上,所以并不是针对谁的函数,而是大家都可以调用
// 如果不使用this,那就需要给identify() 和speak() 显式传入一个上下文对象。
function identify(context) {
return context.name.toUpperCase();
}
function speak(context) {
var greeting = "Hello, I'm " + identify(context);
console.log(greeting);
}
identify(you); // READER
speak(me); //hello, 我是KYLE
// 然而,this 提供了一种更优雅的方式来隐式“传递”一个对象引用,
// 因此可以将API 设计得更加简洁并且易于复用。
this的指向问题
// this 永远指向最后调用它的那个对象
var name = "windowsName";
function a() {
var name = "Cherry";
console.log(this.name); // windowsName
console.log("inner:" + this); // inner: Window
}
a();
var name = "windowsName";
var a = {
name: "Cherry",
fn: function() {
// 在对象属性引用链调用模式下
// 只有最顶层或者说最后一层会影响调用位置,也就是此处的a
console.log(this.name); // Cherry
}
};
window.a.fn();
// 因为this就是指向a,而a中没有定义name
var name = "windowsName";
var a = {
// name: "Cherry",
fn: function() {
console.log(this.name); // undefined
}
};
window.a.fn();
// 这是作用域链起作用,注意与上方的对比
// 此时a只是个对象,并不是一个块级作用域
var name = "windowsName";
var a = {
name: "Cherry",
fn: function() {
console.log(name); // "windowsName"
}
};
window.a.fn();
// 此时fn是个函数,组成了一个块级作用域
// 因此内部作用域屏蔽了全局作用域
var name = "windowsName";
function fn() {
var name = "Cherry";
innerFunction();
function innerFunction() {
console.log(name); // "Cherry"
}
}
fn();
// 虽然innerFunction在函数内部执行的,
// 但并没有带任何修饰的函数引用进行调用的,因此只能使用默认绑定this规则
var name = "windowsName";
function fn() {
var name = "Cherry";
innerFunction();
function innerFunction() {
console.log(this.name); // windowsName
}
}
fn();
// ---------默认绑定this规则-------------
// 注意:虽然this的绑定规则取决于调用位置
// 但对于默认绑定来说,决定this 绑定对象的并不是调用位置是否处于严格模式,
// 而是函数体是否处于严格模式。
// 如果函数体处于严格模式,this 会被绑定到undefined,
// 否则this 会被绑定到全局对象。
function foo() {
"use strict";
// 此时函数体处于严格模式下,会被绑定到undefined
console.log(this.a);
}
var a = 2;
foo(); // TypeError: Cannot read property 'a' of undefined
// 如下,函数体在非严格模式,而执行在严格模式
function foo() {
console.log(this.a);
}
var a = 2;
(function() {
"use strict";
foo(); // 2,正常打印
})();
// 然而如果你把null 或者undefined 作为this 的绑定对象传入call、apply 或者bind,
// 这些值在调用时会被忽略,实际应用的是默认绑定规则。
// 然而,总是使用null 来忽略this 绑定可能产生一些副作用。
// 如果某个函数确实使用了this(比如第三方库中的一个函数),
// 那默认绑定规则会把this 绑定到全局对象(在浏览器中这个对象是window),这将导致不可预计的后果(比如修改全局对象)。
// 如果实在是不在乎被谁调用的话
// 一种“更安全”的做法是传入一个特殊的对象,把this 绑定到这个对象不会对你的程序产生任何副作用
// 创建一个空对象最简单的方法就是Object.create(null),
// 它和{} 很像, 但是并不会创建Object.prototype 这个委托,因此更加干净
function foo(a, b) {
console.log("a:" + a + ", b:" + b);
}
// 创建一个很空很空的对象,这样既不会使用默认绑定规则,也不会产生副作用
var ø = Object.create(null);
// 把数组展开成参数
foo.apply(ø, [2, 3]); // a:2, b:3
// 还可用console.log
console.log.apply(ø, [1, 2, 3]); // 1 2 3
// 等价于
console.log(1, 2, 3);
// 使用bind(..) 进行柯里化
var bar = foo.bind(ø, 2);
bar(3); // a:2, b:3
// ---------改变this的指向-------------
// 1. 使用 ES6 的箭头函数
// 2. 在函数内部使用 _this = this
// 3. 使用 apply、call、bind
// 4. new 实例化一个对象
// 箭头函数的 this 始终指向函数定义时的 this,而非执行时。
// 根据当前的词法作用域来决定 this,具体来说,
// 箭头函数会继承最近一层外层非箭头函数调用的 this 绑定(无论 this 绑定到什么)
var name = "windowsName";
var a = {
name: "Cherry",
func1: function() {
console.log(this.name);
},
func2: function() {
setTimeout(function() {
this.func1(); // this为window
}, 100);
},
func3: function(){
setTimeout(() => {
this.func1();
})
},
func4: () => {console.log(this)}
};
a.func2(); // this.func1 is not a function
a.func3(); // "Cherry",此时this为对象a
a.func4(); // window
// 改造下面代码,让打印10
var b = 10;
(function b(){
b = 20;
// 只需console.log(this.b)
console.log(b); // 默认打印函数体
})();
// ---------使用call,apply,bind-------------
var a = {
// 省略
func2: function() {
// apply或call
setTimeout(
function() {
this.func1();
}.call(a),
100
);
// bind,需要调用
setTimeout(
function() {
this.func1();
}.bind(a)(),
100
);
}
};
// ---------apply语法-------------
// MDN:apply() 方法调用一个函数, 其具有一个指定的this值,
// 以及作为一个数组(或类似数组的对象)提供的参数
fun.apply(thisArg, [argsArray]);
// 其实就是thisArg对象调用fun函数。因此this指向thisArg
// 如果传入的是null,undefined,则会被忽略,其实还是应用的默认规则
// 如果传入原始类型,则会自动指向对应的包装类型
// argsArray为一个数组或类数组
// ---------call语法-------------
// 除了传参模式与apply不同,其他都相同
// fun.call(thisArg[, arg1[, arg2[, ...]]])
// ---------bind语法-------------
// thisArg调用绑定函数时作为this参数传递给目标函数的值
// arg1, arg2,...当目标函数被调用时,预先添加到绑定函数的参数列表中的参数。
// function.bind(thisArg[, arg1[, arg2[, ...]]])
// 示例
var p = {};
function person(name, age) {
console.log(this, name, age);
}
var fn = person.bind(p, "manster", "23");
fn(); // {} "manster" "23"
function add(x, y) {
return x + y;
}
console.log(add(1, 2)); // 3
// 修改为柯理化
function add2(x) {
return function(y) {
return x + y;
};
}
console.log(add2(1)(2)); // 3
// 手写bind函数:
// 此时定义的myBind是多个参数
Function.prototype.myBind = function(context, ...args) {
return () => this.apply(context, args);
};
// 测试一下
let obj1 = { name: "test1" };
let func1 = function(p1, p2) {
console.log(this.name); // 'test1'
console.log(p1, p2); // 1 2
};
let fn = func1.myBind(obj1, 1, 2);
fn();
// 上面代码将func1的this指向了obj了,因此就可以打印出obj里的name属性。。。
// 另外,修改this指向时传入了参数1,2也同样打印出来了。。。
// 但fn()调用时没有传参,如果再继续传参又该如何处理呢?
Function.prototype.myBind = function (context, ...args){
// 要记住,返回的是一个函数,如果想执行的话,则需要调用
return (...args2) => {
this.apply(context, [...args, ...args2]);
};
};
// 测试一下
let obj2 = { name: "test2" };
let func2 = function(p1, p2, p3, p4) {
console.log(this.name); // 'test2'
console.log(p1, p2, p3, p4); // 1 2 3 4
};
let fn = func2.myBind(obj2, 1, 2);
fn(3, 4);
// ---------this指向规则判断优先级(完结)-------------
// 1. 函数是否在new 中调用(new 绑定)?如果是的话this 绑定的是新创建的对象。
var bar = new Foo();
// 2. 函数是否通过call、apply(显式绑定)或者硬绑定调用?如果是的话,this 绑定的是指定的对象。
var bar = foo.call(obj2);
// 3. 函数是否在某个上下文对象中调用(隐式绑定)?如果是的话,this 绑定的是那个上下文对象。
var bar = obj1.foo();
// 4. 如果都不是的话,使用默认绑定。如果在严格模式下,就绑定到undefined,否则绑定到全局对象。
var bar = foo();
// 注意:对于正常的函数调用来说,理解了这些知识你就可以明白this 的绑定原理了。不过……凡事总有例外。
// 也就是如果把null 或者undefined 作为this 的绑定对象传入call、apply 或者bind,
// 这些值在调用时会被忽略,实际应用的是默认绑定规则
柯力化
// 柯里化,可以理解为提前接收部分参数,延迟执行,不立即输出结果,
// 而是返回一个接受剩余参数的函数。
// 思考一个场景,设计一个算法记录一个月的加班时间?
// 常规方法是首先记录每天加班时间,然后再将每天的时间相加。。。
var monthTime = 0;
function overtime(time) {
return (monthTime += time);
}
overtime(3.5); // 第一天
overtime(4.5); // 第二天
overtime(2.1); // 第三天
//...
console.log(monthTime); // 10.1
// 缺点:浪费性能,没有必要每天都计算,尤其数据量大的时候
// 因此我们可以只保存每天的加班时间,到月底只计算一次就好。。。
function currying(fn) {
var allArgs = [];
// 利用闭包,将allArgs一直保存在内存中
return function next() {
var args = [].slice.call(arguments);
if (args.length > 0) {
// 收集参数,进行缓存
allArgs = allArgs.concat(args);
return next;
} else {
// 符合执行条件,执行计算
return fn.apply(null, allArgs);
}
};
}
var add = currying(function() {
var sum = 0;
for (var i = 0; i < arguments.length; i++) {
sum += arguments[i];
}
return sum;
});
// 因为是根据有无参数来决定是否执行计算,最后传空表示可以计算
// 参考下面方法四更简单
add(3.5)(4.5)(2.1)(); // 10.1
// 扩展:
// 实现 add(1)(2, 3)(4)(5) === 15 的效果。
// 此时怎么知道执行的时机呢?
// 其实,这里有个忍者技艺:valueOf和toString。
// js在获取当前变量值的时候,会根据语境,隐式调用valueOf和toString方法进行获取需要的值。
// 因此,代码如下(弊端是覆盖原型上的toString和valueOf,设计到隐式转换的都会触发)
function currying(fn) {
var allArgs = [];
function next() {
var args = [].slice.call(arguments);
allArgs = allArgs.concat(args);
return next;
}
// 字符类型
next.toString = function() {
return fn.apply(null, allArgs);
};
// 数值类型
next.valueOf = function() {
return fn.apply(null, allArgs);
};
return next;
}
var add = currying(function() {
var sum = 0;
for (var i = 0; i < arguments.length; i++) {
sum += arguments[i];
}
return sum;
});
// 以下是几种柯力化方法,
// 方法一
let currying = (fn, length, ...args) =>
args.length === length
? fn(...args)
: currying.bind(null, fn, args.length, ...args);
// 方法二
const curry = (fn, arr = []) => (...args) =>
(arg => (arg.length === fn.length ? fn(...arg) : curry(fn, arg)))([
...arr,
...args
]);
// 方法三
// 参考:https://juejin.im/post/5bf9bb7ff265da616916e816
const curry = fn => {
if (fn.length <= 1) return fn;
const generator = args =>
args.length === fn.length ? fn(...args) : arg => generator([...args, arg]);
return generator([], fn.length);
};
// 测试
const sum = (a, b, c) => a + b + c;
const curriedSum = curry(sum);
const res = curriedSum(1)(2)(3);
console.log(res); // 6
const log = (a, b, c) => {
console.log(a, b, c);
};
const curriedLog = curry(log);
curriedLog("a")("b")("c"); // a b c
// 方法四
// 参考:https://juejin.im/post/5bf18715e51d45244939acc5
function curry(fn, ...args) {
return (..._arg) => {
return fn(...args, ..._arg);
};
}
function sum() {
let mySum = 0;
for (let i = 0; i < arguments.length; i++) {
mySum += arguments[i];
}
return mySum;
}
curry(sum, 1, 2)(); // 3
curry(sum, 1, 2, 3)(); // 6
// ---------反柯力化-------------
// 反柯里化的作用是,当我们调用某个方法,不用考虑这个对象在被设计时,
// 是否拥有这个方法,只要这个方法适用于它,我们就可以对这个对象使用它。
手写promise
// 手写promise
// 参考:https://juejin.im/post/5c6ad98e6fb9a049d51a0f5e
// 参考:https://juejin.im/post/5b2f02cd5188252b937548ab
// 都是基于PromiseA+规范:https://promisesaplus.com/
// 结构一需满足
// 1. new Promise(executor)中参数executor(执行器)是函数,且自动执行,
// 2. 执行器可执行resolve或者reject,且都是函数
class Promise {
// 构造器
constructor(executor) {
// 成功
let resolve = () => {};
// 失败
let reject = () => {};
// 立即执行
executor(resolve, reject);
}
}
// 结构二需满足
// 1. 三种状态(state):pending、fulfilled、rejected
// 2. pending为初态,可转化为fulfilled(成功态)和rejected(失败态)
// 3. 成功后,不可再转为其他状态,且必须有一个不可改变的值(value)
// 4. 失败后,不可再转为其他状态,且必须有一个不可改变的原因(reason)
// 5. resolve为成功,接收参数value,状态改变为fulfilled,不可再次改变。
// 6. reject为失败,接收参数reason,状态改变为rejected,不可再次改变。
// 7. 若是executor函数报错 直接执行reject();
class Promise {
constructor(executor) {
// 初始态
this.state = "pending";
this.value = undefined;
this.reason = undefined;
let resolve = value => {
// 只有pending可变为其他
if (this.state === "pending") {
// 修改状态
this.state = "fulfilled";
this.value = value;
}
};
let reject = reason => {
if (this.state === "pending") {
this.state = "rejected";
this.reason = reason;
}
};
// 如果executor执行报错,直接执行reject
try {
executor(resolve, reject);
} catch (err) {
reject(err);
}
}
}
// 结构三需满足
// 1. 具有then方法,且then方法有两个参数onFulfilled,onRejected
// 2. 当状态是fulfilled,执行onFulfilled,传入value
// 3. 当状态是rejected,执行onRejected,传入reason
// 4. 如果onFulfilled,onRejected是函数,分别在对应状态改变后执行,
// value或reason依次作为他们的第一个参数
class Promise1 {
constructor(executor) {
// 初始态
this.state = "pending";
this.value = undefined;
this.reason = undefined;
let resolve = value => {
// 只有pending可变为其他
if (this.state === "pending") {
// 修改状态
this.state = "fulfilled";
this.value = value;
}
};
let reject = reason => {
if (this.state === "pending") {
this.state = "rejected";
this.reason = reason;
}
};
// 如果executor执行报错,直接执行reject
try {
executor(resolve, reject);
} catch (err) {
reject(err);
}
}
then(onFulfilled, onRejected) {
if (this.state === "fulfilled") {
onFulfilled(this.value);
}
if (this.state === "rejected") {
onRejected(this.reason);
}
}
}
// 测试一把
var p = new Promise1((resolve, reject) => {
console.log("start");
resolve("msg");
});
p.then(
val => {
console.log(val);
},
reason => {
console.log(reason);
}
);
console.log("end");
// 顺序还有问题
// start msg end
// 结构四需满足
// 结构三对于同步代码没有问题,但是异步则不行
// 1. 若处在pendding时就调用then,需将对应的回调存到各自数组
// 2. 当状态改变后,再执行数组中存的回调(类似订阅发布模式)
// 3. 一个promise可以有多个并列的then(不是链式)
class Promise2 {
constructor(executor) {
this.state = "pending";
this.value = undefined;
this.reason = undefined;
// 成功存放的数组
this.onResolvedCallbacks = [];
// 失败存放法数组
this.onRejectedCallbacks = [];
let resolve = value => {
if (this.state === "pending") {
this.state = "fulfilled";
this.value = value;
// 一旦resolve执行,调用成功数组的函数
this.onResolvedCallbacks.forEach(fn => fn());
}
};
let reject = reason => {
if (this.state === "pending") {
this.state = "rejected";
this.reason = reason;
this.onRejectedCallbacks.forEach(fn => fn());
}
};
// 如果executor执行报错,直接执行reject
try {
executor(resolve, reject);
} catch (err) {
reject(err);
}
}
then(onFulfilled, onRejected) {
if (this.state === "fulfilled") {
onFulfilled(this.value);
}
if (this.state === "rejected") {
onRejected(this.reason);
}
// 和非pending态比,只是没有执行的函数而已
if (this.state === "pending") {
this.onResolvedCallbacks.push(() => {
onFulfilled(this.value);
});
this.onRejectedCallbacks.push(() => {
onRejected(this.reason);
});
}
}
}
// 结构五需满足
// 1. 满足链式new Promise().then().then()
// 1-1. 第一个then可返回一个promise,并传递给下一个then
// 1-2. 第一个then还可返回一个普通值,并传递给下一个then
// 2. 判断第一个then的返回值(这里用x代替)
// 2-1. 首先,要看x是不是promise。
// 2-2. 如果是promise,则取它的结果,作为新的promise2成功的结果
// 2-3. 如果是普通值,直接作为promise2成功的结果
// 2-4. 所以要比较x和promise2
// 2-5. resolvePromise的参数有promise2(默认返回的promise)、x(我们自己return的对象)、resolve、reject
// 2-6. resolve和reject是promise2的
class Promise {
constructor(executor) {
this.state = "pending";
this.value = undefined;
this.reason = undefined;
this.onResolvedCallbacks = [];
this.onRejectedCallbacks = [];
let resolve = value => {
if (this.state === "pending") {
this.state = "fulfilled";
this.value = value;
this.onResolvedCallbacks.forEach(fn => fn());
}
};
let reject = reason => {
if (this.state === "pending") {
this.state = "rejected";
this.reason = reason;
this.onRejectedCallbacks.forEach(fn => fn());
}
};
try {
executor(resolve, reject);
} catch (err) {
reject(err);
}
}
then(onFulfilled, onRejected) {
// 声明返回的promise2
let promise2 = new Promise((resolve, reject) => {
if (this.state === "fulfilled") {
// 注意x来自这里
let x = onFulfilled(this.value);
// resolvePromise函数,处理x和默认的promise2
resolvePromise(promise2, x, resolve, reject);
}
if (this.state === "rejected") {
let x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
}
if (this.state === "pending") {
this.onResolvedCallbacks.push(() => {
let x = onFulfilled(this.value);
resolvePromise(promise2, x, resolve, reject);
});
this.onRejectedCallbacks.push(() => {
let x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
});
}
});
// 返回promise,完成链式
return promise2;
}
}
// resolvePromise函数
// 规范规定一段代码,让不同的promise代码互相套用,这就是resolvePromise
// 1. 如果 x === promise2,则是会造成循环引用,自己等待自己完成,则报“循环引用”错误
// 2. 判断x
// 2-1. x 不能是null
// 2-2. x 是普通值 直接resolve(x)
// 2-3. x 是对象或者函数(包括promise),let then = x.then
// 2-4. 如果取then报错,则走reject()
// 2-5. 如果then是个函数,则用call执行then,第一个参数是this,后面是成功的回调和失败的回调
// 2-6. 如果成功的回调还是pormise,就递归继续解析
// 2-7. 成功和失败只能调用一个 所以设定一个called来防止多次调用
function resolvePromise(promise2, x, resolve, reject) {
// 循环引用报错
if (x === promise2) {
// reject报错
return reject(new TypeError("Chaining cycle detected for promise"));
}
// 防止多次调用
let called;
// x不是null 且x是对象或者函数
if (x != null && (typeof x === "object" || typeof x === "function")) {
try {
// A+规定,声明then = x的then方法
let then = x.then;
// 如果then是函数,就默认是promise了
if (typeof then === "function") {
// 就让then执行 第一个参数是this 后面是成功的回调 和 失败的回调
then.call(
x,
y => {
// 成功和失败只能调用一个
if (called) return;
called = true;
// resolve的结果依旧是promise 那就继续解析
resolvePromise(promise2, y, resolve, reject);
},
err => {
// 成功和失败只能调用一个
if (called) return;
called = true;
reject(err); // 失败了就失败了
}
);
} else {
resolve(x); // 直接成功即可
}
} catch (e) {
// 也属于失败
if (called) return;
called = true;
// 取then出错了那就不要在继续执行了
reject(e);
}
} else {
resolve(x);
}
}
// 结构六,其他问题
// 1. 规范规定onFulfilled,onRejected都是可选参数,如果他们不是函数,必须被忽略
// 1-1. onFulfilled返回一个普通的值,成功时直接等于 value => value
// 1-2. onRejected返回一个普通的值,失败时如果直接等于 value => value,
// 则会跑到下一个then中的onFulfilled中,所以直接扔出一个错误reason => throw err
// 2. 规范规定onFulfilled或onRejected不能同步被调用,必须异步调用。
// 2-1. 我们就用setTimeout解决异步问题
// 2-2. 如果onFulfilled或onRejected报错,则直接返回reject()
class Promise {
constructor(executor) {
this.state = "pending";
this.value = undefined;
this.reason = undefined;
this.onResolvedCallbacks = [];
this.onRejectedCallbacks = [];
let resolve = value => {
if (this.state === "pending") {
this.state = "fulfilled";
this.value = value;
this.onResolvedCallbacks.forEach(fn => fn());
}
};
let reject = reason => {
if (this.state === "pending") {
this.state = "rejected";
this.reason = reason;
this.onRejectedCallbacks.forEach(fn => fn());
}
};
try {
executor(resolve, reject);
} catch (err) {
reject(err);
}
}
then(onFulfilled, onRejected) {
// onFulfilled如果不是函数,就忽略onFulfilled,直接返回value
onFulfilled =
typeof onFulfilled === "function" ? onFulfilled : value => value;
// onRejected如果不是函数,就忽略onRejected,直接扔出错误
onRejected =
typeof onRejected === "function"
? onRejected
: err => {
throw err;
};
let promise2 = new Promise((resolve, reject) => {
if (this.state === "fulfilled") {
// 异步
setTimeout(() => {
try {
let x = onFulfilled(this.value);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
}, 0);
}
if (this.state === "rejected") {
// 异步
setTimeout(() => {
// 如果报错
try {
let x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
}, 0);
}
if (this.state === "pending") {
this.onResolvedCallbacks.push(() => {
// 异步
setTimeout(() => {
try {
let x = onFulfilled(this.value);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
}, 0);
});
this.onRejectedCallbacks.push(() => {
// 异步
setTimeout(() => {
try {
let x = onRejected(this.reason);
resolvePromise(promise2, x, resolve, reject);
} catch (e) {
reject(e);
}
}, 0);
});
}
});
// 返回promise,完成链式
return promise2;
}
}
// Promise.resolve方法
Promise.resolve = function(val) {
return new Promise((resolve, reject) => {
resolve(val);
});
};
// Promise.reject方法
Promise.reject = function(val) {
return new Promise((resolve, reject) => {
reject(val);
});
};
// Promise.race方法
Promise.race = function(promises) {
return new Promise((resolve, reject) => {
for (let i = 0; i < promises.length; i++) {
promises[i].then(resolve, reject);
}
});
};
// Promise.all方法(获取所有的promise,都执行then,把结果放到数组,一起返回)
Promise.all = function(promises) {
let arr = [];
let i = 0;
function processData(index, data) {
arr[index] = data;
i++;
if (i == promises.length) {
resolve(arr);
}
}
return new Promise((resolve, reject) => {
for (let i = 0; i < promises.length; i++) {
promises[i].then(data => {
processData(i, data);
}, reject);
}
});
};
// 其他方式实现Promise.all
if (!Promise.all) {
Promise.all = function(promiseArray) {
return new Promise(function(resolve, reject) {
//判断参数类型
if (!Array.isArray(promiseArray)) {
return reject(new TypeError("arguments muse be an array"));
}
var counter = 0,
promiseNum = promiseArray.length,
resolvedArray = new Array(promiseNum);
for (var i = 0; i < promiseNum; i++) {
(function(i) {
Promise.resolve(promiseArray[i]).then(
function(value) {
counter++;
// resolvedArray.push(value);
resolvedArray[i] = value; // 原始运算符始终比函数调用要高效
if (counter == promiseNum) {
return resolve(resolvedArray);
}
},
function(reason) {
return reject(reason);
}
);
})(i);
}
});
};
}
// 可以用promises-aplus-tests包测试
基本数据类型
ECMAScript标准规定了7种数据类型,分两种:原始类型和引用类型
原始类型:
- Null:只包含一个值:null
- Undefined:只包含一个值:undefined
- Boolean:包含两个值:true和false
- Number:整数或浮点数,还有一些特殊值(-Infinity、+Infinity、NaN)
- String:一串表示文本值的字符序列
- Symbol:一种实例是唯一且不可改变的数据类型
- BigInt:es10(ECMAScript2019)
引用类型:
- Object,
typeof
鉴于 ECMAScript 是松散类型的,因此需要一种手段来检测变量的数据类型,typeof就是负责提供这方面信息的操作符。
typeof "hello"; // 'string'
typeof true; // 'boolean'
typeof 100; // 'number'
typeof undefined; // 'undefined'
typeof null; // 'object'
typeof function() {}; // 'function'
Null 与 Undefined
注意:typeof是一个操作符而不是函数,因此例子中的圆括号可以使用,但不是必需的。这里typeof null返回'object',因为null被认为是一个空的对象引用,其实更底层原因是因为不同的对象在计算机底层都表示为二进制,在JavaScript中二进制前三位都为 0 的话会被判断为 object 类型,null的二进制表示是全 0,自然前三位也是 0,所以执行typeof 时会返回'object'。
null表示”没有对象”,即该处不应该有值。undefined表示”缺少值”,就是此处应该有一个值,但是还没有定义。
注意:对未经声明或未初始化的变量,使用typeof都会返回'undefined',但无法使用delete删除一个直接通过var声明的全局变量
var aa;
typeof aa; // 'undefined'
typeof bb; // 'undefined'
delete aa; // false
delete bb; // true
// 另外注意
null == undefined; // true , 实际上undefined值是派生自null值的(null出现的早)
null === 0 ; // true ,+ 其实就是数字转化,相当于Number(null)
Number(null) === 0; // true
-null === -0; // true , - 也是数字转化,但有符号问题
+ 0 === -0; // true
如果定义的变量准备在将来用于保存对象,那么最好将该变量初始化为null而不是其他值。这样只要直接检测是否为null就可以知道变量是否已经保存一个对象的引用了。
instanceof
。typeof是检测字符串、数值、布尔值、undefined的最佳工具,但对于对象或null,则都返回'object'。因此在检测引用类型的值时用途不大,因为我们并不是想知道某个值是对象,而是想知道它是什么类型的对象,因此出现了instanceof操作符,用于测试构造函数的 prototype 属性是否出现在对象的原型链中的任何位置。
如果变量是给定引用类型的实例,那么instanceof就会返回true。根据规定,所有引用类型都是Objcet的实例,因此在检测引用类型值与Objcet构造函数时,instanceof都会返回true,如果检测基本类型,则都会false,因为基本类型不是对象。。。
在 ECMA-262 规范中,凡是内部实现[[call]]方法的对象,typeof检测都返回'function',由于正则也实现了,因此也会返回'function'。。。但现代浏览器普遍都返回'object'
Number
Number 类型在 ECMAScript 中,使用IEEE754格式来表示整数和浮点数(又称双精度数值)。常见的格式有 10,2,8,16 进制等。
8 进制的第一位必须是 0,然后是 8 进制数字(0~7),如果字面值中的数字超过了(0~7),那么前导 0 被忽略,后面的数值将当做 10 进制解析,如下
var octalNum1 = 070; // 8进制56 即 (7 * 8 + 0 * 8)
var octalNum2 = 079; // 无效的8进制,丢弃前导0,后面解析为10进制,即79
var octalNum3 = 08; // 无效的8进制,丢弃前导0,后面解析为10进制,即8
注意:在严格模式下,8 进制前导 0 变为0o,即
var num1 = 0o71; // 8进制57 即 (7 * 8^1 + 1 * 8^0)
十六进制字面量的前两位必须是0x,后面跟十六进制数字(0~9 及 A-F),字母大小写均可。在进行算术计算时,所有八进制和十六进制表示的数值最终都将被转换为十进制数值。
var hexNum1 = 0xa; // 十六进制10
var hexNum2 = 0xa; // 十六进制10
var hexNum3 = 0x1f; // 十六进制31 即 1 * 16^1 + 15 * 16^0
浮点数
所谓浮点数,就是该数值必须包含一个小数点,且小数点后面至少有一个数字,虽然小数点前可以没有数字但不推荐。由于浮点数需要的内存空间是整数值的两倍,因此 ECMAScript 会不失时机的将浮点数转换为整数值。显然,如果小数点后面没有任何数字(如:1.),或本身就是一个整数(如:10.0),则都会转换成整数。
对于那些极大或极小的数值,可以用 e 表示法(科学计数法)表示的浮点数表示。e 表示法表示的数值等于 e 前面的数值乘以 10 的指数次幂
var floatNum1 = 3.125e7; // 等于31250000,即3.125 * 10^7
var floatNum2 = 0.0000003; // 等于3e-7
浮点数的最高精度是 17 位小数,但在进行算术运算时其精确度远远不如整数,如:
0.1 + 0.2 === 0.30000000000000004; // 小数点后正好17位
0.15 + 0.15 === 0.3; // true
注意:关于浮点数值计算会产生舍入误差的问题,这是因为使用基于IEEE754数值的浮点计算的通病,ECMAScript 并非独此一家,其他使用相同数值格式的语言也存在这个问题。当然如果只是想表面的’修复’此问题,可以如下:
// 注意结果有的为字符串格式
(0.1 + 0.2).toFixed(10); // '0.3000000000'
parseFloat((0.1 + 0.2).toFixed(10)); // 0.3
( 0.1 + 0.2 ).toPrecision(1); // '0.3'
parseFloat((0.1 + 0.2).toPrecision(1)); // 0.3
数值范围
由于内存的限制,ECMAScript 无法存储所有数值,ECMAScript 能够表示的最小,最大以及溢出如何处理如下:
// 针对大多数浏览器
Number.MAX_VALUE; // 保存着最大值 1.7976931348623157e+308
Number.MIN_VALUE; // 保存着最小值 5e-324
Number.MAX_VALUE * 2; // 最大值溢出,显示为Infinity
Number.MIN_VALUE - 2e308; // 最小值溢出,显示为-Infinity
Number.MIN_VALUE - 2e307; // -2e+307
Number.MIN_VALUE - 2; // -2,此时和精度有关
Number.MIN_VALUE / 2; // 0,此时和精度有关
Number.POSITIVE_INFINITY; // Infinity,保存着溢出后的最大值
Number.NEGATIVE_INFINITY; // -Infinity,保存着溢出后的最小值
注意:上面例子中如果想模拟溢出最小值,会有点出乎意料,但其实这是精度的问题,而且也就从 308 开始显示为-Infinity,而 308 也和最大值呼应起来。检测某个值是否在最大值与最小值之间,可以如下:
var overflowMaxVal = Number.MAX_VALUE * 2;
var overflowMinVal = Number.MIN_VALUE - 2e308;
isFinite(overflowMaxVal); // false
isFinite(overflowMinVal); // false
isFinite(666); // true
NaN
NaN,即非数值(not a number),是一个特殊的数值,用来表示一个本来要返回数值的操作数未返回数值的情况(这样在程序运行中就不会抛出错误了),它有两个特点:
- 任何涉及 NaN 的操作都返回 NaN(如:NaN / 2)
- 不等于任何值(包括自身,NaN === NaN 为 false)
当然可以利用isNaN()函数来检测是否为 NaN,这个函数在接收一个值以后,会尝试将这个值转为数值,如果不能转换为数值就会返回 true。
isNaN(NaN); // true
isNaN("string"); // true
isNaN(undefined); // true
isNaN({}); // true
isNaN(10); // false
isNaN("10"); // false,'10'会被转换10
isNaN(true); // false,true会被转换1
isNaN(null); // false,null会被转换0
isNaN()函数也可以传入对象,此时会先调用对象的valueOf()方法,然后确定该方法返回的值是否可以转换为数值,如果不能,则基于这个返回值再调用toString()方法,再测试其返回值。
注意: typeof NaN === 'number',也印证了NaN是一个特殊的数字。
数值转化
有三个函数可以把非数值转化为数值:Number()、parseInt()、parseFloat(),Number()适用于所有数据类型,其他两个专门用于将字符串转为数值。Number()转换规则如下:
- 如果是
Boolean值,true和false分别转为 1 和 0 - 如果是数值,只是简单的传入和返回
- 如果是
null,返回 0 - 如果是
undefined,返回NaN -
如果是字符串,则有以下规则
- 字符串只包含数字(可以有正负号),则转为 10 进制,如:’1’ => 1,’-123’ => -123,’011’ => 11(忽略前导 0)
- 字符串只包含浮点格式(可以有正负号),则转为对应浮点数值,忽略前导 0,如:’-01.1’ => -1.1
- 字符串包含十六进制格式,转换为 10 进制,如:’0xa’ => 10,’-0xa’ => NaN
- 字符串为空(空格’ ‘或’’),转换为 0
- 如果字符串中包含上述格式以外的字符,转为
NaN
- 如果是对象(如果是
Date对象可直接调用toString()),先调用对象的valueOf()方法,然后确定该方法返回的值是否为原始值,如果不是,则基于这个返回值再调用toString()方法,然后依次按照前面的规则转换返回的字符串值。
valueOf
object.valueOf()方法返回该对象的原始值,而ECMAScript 规定的变量可以存储在两种类型的值:原始值和引用值。
- 原始值:存储在栈(stack)中的简单数据段,他们的值直接存储在变量访问的位置
- 引用值:存储在堆(heap)中的对象,存储在变量处的值是一个指针(point),指向存储对象的内存处
为变量赋值时,ECMAScript 的解释程序必须判断该值是原始类型,还是引用类型。要实现这一点,解释程序则需尝试判断该值是否为 ECMAScript 的原始类型之一,即 Undefined、Null、Boolean、Number和 String型。由于这些原始类型占据的空间是固定的,所以可将他们存储在较小的内存区域 - 栈中。这样存储便于迅速查寻变量的值。
如果一个值是引用类型的,那么它的存储空间将从堆中分配。由于引用值的大小会改变,所以不能把它放在栈中,否则会降低变量查寻的速度。相反,放在变量中的值是该对象存储在堆中的地址。地址的大小是固定的,所以把它存储在栈中对变量性能无任何负面影响。
另外:引用类型的值是保存在内存中的对象,与其他语言不同,js 不允许直接访问内存中的位置,在操作对象时,实际操作的是对象的引用而不是实际的对象。
JavaScript 调用valueOf方法将对象转换为原始值。你很少需要自己调用valueOf方法;当遇到要预期的原始值的对象时,JavaScript 会自动调用它。
默认情况下,valueOf方法由 Object 后面的每个对象继承。 每个内置的核心对象都会覆盖此方法以返回适当的值。如果对象没有原始值,则valueOf将返回对象本身。
JavaScript 的许多内置对象都重写了该函数,以实现更适合自身的功能需要。因此,不同类型对象的valueOf()方法的返回值和返回值类型均可能不同。
| 对象 | 返回值 |
|---|---|
| Array | 返回数组对象本身 |
| Boolean | 布尔值。 |
| Date | 存储的时间是从 1970 年 1 月 1 日午夜开始计的毫秒数 UTC。 |
| Function | 函数本身。 |
| Number | 数字值 |
| Object | 对象本身。这是默认情况。 |
| String | 字符串值 |
| Math、Error 对象没有 valueOf 方法 |
既然可以重写,那下面的问题就很简单了:
// 如何让 a == 1 && a == 2 && a == 3
const a = {
value: [3,2,1],
valueOf(){ return this.value.pop() }
}
a == 1 && a == 2 && a == 3; // true
// 其实下面的这几个没必要调用valueOf,因为都是原始值
1.230.valueOf() // 1.23
'1.230'.valueOf() // '1.230'
true.valueOf() // true
null.valueOf() // Cannot read property 'valueOf' of null
undefined.valueOf() // 同上
// Date对象转换后,直接就是数字了,直接调用数字转化规则
new Date().valueOf() // 1551667119234 距今的毫秒数
// 下面几个对象转换之后仍然是对象,因此需要再调用toString()
[].valueOf() // []
["ABC", true, 12, -5].valueOf() // ["ABC", true, 12, -5]
({}).valueOf() // {}
({a:1}).valueOf() // {a:1}
(function(){}).valueOf() // function(){}
[].valueOf().toString() // ''
["ABC", true, 12, -5].valueOf().toString() // "ABC,true,12,-5"
({}).valueOf().toString() // "[object Object]"
({a:1}).valueOf().toString() // "[object Object]"
(function(){}).valueOf().toString() // "function(){}"
注意:({}).valueOf(),这里的{}用()包括起来了,这是因为避免解析器将{}解析为代码块,此处应该为对象,所以包裹起来。
上面便是数字转化的规则,因此遇到需要隐式转换的场景,应该熟练上述转化:
console.log(1 + "5"); // "15"
console.log([1, 3, 5] + 1); // "1,3,51"
console.log(10 + true); // 11
console.log(15 + {}); // "15[object Object]"
console.log(8 + null); // 8
console.log("queen" + null); // "queennull"
console.log({} + null); // "[object Object]null"
console.log(12 + undefined); // NaN
console.log("w3cplus" + undefined); // "w3cplusundefined"
console.log([] + null); // "null"
console.log([] + undefined); // "undefined"
console.log([] + "w3cplus"); // "w3cplus"
知道了对象转化为数字的规则,则当有加法运算时(其实一元加操作符的操作与Number()函数相同),也有一定规则:
- 如果操作符数中有一个对象,它将转换为原始值
- 如果操作符数中有一个字符串,第二个操作数将转换成字符串,并且连接在一起转换成一个字符串(和顺序无关)
- 在其它情况之下,两个操作数转换为数字并且将执行加法运算
// 前置减号和前置加号,都优先转换为数字再计算
console.log(+"12" + "34"); // '1234'
console.log(+"12" + 34); // 46
console.log(+12 + "34"); // '1234'
console.log(+12 + 34); // 46
console.log(-"12" + "34"); // '-1234'
console.log(-"12" + 34); // 22
console.log(-12 + "34"); // '-1234'
console.log(-12 + 34); // 22
// 减号在中间,两侧都转换为数值,否则为NaN
console.log("11" + 2 - "1"); // 111 数字
console.log("12" - "34"); // -22
console.log("12" - "34a"); // NaN
console.log("12" - 34); // -22
console.log(12 - "34"); // -22
console.log(12 - 34); // -22
parseInt() & parseFloat()
Number()函数在转换字符串时,比较复杂繁琐,parseInt()、parseFloat()则更加单纯,更多的是看是否符合数值模式。首先来看parseInt()的规则:
- 忽略字符串前面的空格
- 找到第一个非空格字符
- 若第一个字符不是数字或正负号,则返回 NaN
- 若第一个字符有效,则继续后面的字符,直到遇到非数字字符
- 若第一个字符有效,还可以识别出各种整数格式(二、八、十六进制)
parseInt(" "); // NaN,而Number(' ') => 0
parseInt("1.1"); // 1, 符号.在parseInt里为无效符号
parseInt("123abc"); // 123
parseInt("0xf"); // 15
parseInt("071"); // 57,在ES3引擎上为8进制
注意:parseInt('071')在 ES3 和 ES5 引擎上表现不一致,在 ES3 上被认为是八进制,因此值为 57,但在 ES5 引擎上,parseInt()不具有解析八进制值得能力(十六进制仍然可以),因此前导 0 会被认为无效,从而返回 0,结果就是十进制的 0
从 ES5 开始,在严格模式之中,八进制就不再允许使用前缀 0 表示,ES6 提供了二进制和八进制数值的新的写法,分别用前缀 0b(或 0B)和 0o(或 0O)表示。
在现在 chrome 浏览器,有以下行为:
parseInt("011", 2); // 3
parseInt("011"); // 11
parseInt("071"); // 71
parseInt("071", 8); // 57
parseInt("0o71"); // 0
parseInt("0o71", 8); // 0
parseInt("0b11"); // 0
为了消除parseInt()函数可能导致的上述问题,可以为这个函数提供第二个参数,转换时使用的基数,如果知道要解析的值是 16 进制,那么就指定 16 作为第二个参数,以保证得到正确的结果。而且若指定了第二个参数,还可以不带’0x’
注意:parseInt 方法的可选参数是操作数的进制说明,不是要转化的目标的进制。要想进制转换可以利用Number.prototype.toString()
// string 要被解析的值。如果参数不是一个字符串,则将其转换为字符串(使用toString 抽象操作)
// radix 一个介于2和36之间的整数(数学系统的基础),表示上述字符串的基数。当未指定基数时,不同的实现会产生不同的结果,通常将值默认为10,如果指定0也按10处理。
parseInt(string, radix);
// 以下例子均返回15
parseInt("0xF", 16);
parseInt("F", 16);
parseInt("17", 8);
parseInt(021, 8); // 和parseInt('021', 8) => 17不同
parseInt("015", 10); // parseInt(015, 10); 返回 15
parseInt(15.99, 10);
parseInt("15,123", 10);
parseInt("FXX123", 16);
parseInt("1111", 2);
parseInt("15 * 3", 10);
parseInt("15e2", 10);
parseInt("15px", 10);
parseInt("12", 13);
// 以下例子均返回 NaN:
parseInt("Hello", 8); // 根本就不是数值
parseInt("546", 2); // 除了“0、1”外,其它数字都不是有效二进制数字
// 以下例子均返回 -15:
parseInt("-F", 16);
parseInt("-0F", 16);
parseInt("-0XF", 16);
parseInt(-15.1, 10);
parseInt(" -17", 8);
parseInt(" -15", 10);
parseInt("-1111", 2);
parseInt("-15e1", 10);
parseInt("-12", 13);
// 下例中也全部返回 17,因为输入的 string 参数以 "0x" 开头时作为十六进制数字解释,而第二个参数假如经过 Number 函数转换后为 0 或 NaN,则将会忽略而仍然解析为十六进制
parseInt("0x11", 16);
parseInt("0x11", 0);
parseInt("0x11", NaN);
// 如果给十六进制数传其他进制,则无法识别,直接返回0
parseInt("0x11", 8); // 0
// 另外被解析参数的第一个字符若无法被转换,则返回NaN
parseInt("211", 2); // 返回 NaN,因为二进制不可能有2
parseInt("a11", 2); // 返回 NaN,因为二进制无法转换a字符
注意:parseInt(021, 8)与parseInt('021', 8)不同,前者的参数一是数字,而后者是字符串。字符串的话则直接按照给定的基数进行解析。而数字的话,js 默认 0 开头的是 8 进制,因此 021 对应的就是 17,然后第二个参数是 8,也就是让浏览器认为这个 17 也是 8 进制的,因此 17 再按照8进制转换后为 15(1 * 8 + 7 * 8^0)。同理遇见 0x 开头的则为 16 进制,也是需要先转成对应的 10 进制,然后再按照基数转一次。
parseInt(021, 8); // 15
parseInt(0x21, 8); // 27, 2*16^1 + 1 => 33, 33 => 3*8^1 + 3 => 27
parseInt(022, 8); // 1, 2*8 + 2 => 18 ,18的8对于8进制无效,因此为1
parseInt(019, 8); // 1, 019的9是非法8进制数,因此只识别01也就是1,再转一次也是1
parseFloat()在解析过程中遇到了正负号(+或-),数字(0-9),小数点,或者科学记数法中的指数(e 或 E)以外的字符,则它会忽略该字符以及之后的所有字符,返回当前已经解析到的浮点数.同时参数字符串首位的空白符会被忽略。
但字符串中的第二个小数点是无效的,如parseFloat('22.33.5') => 22.34。另外就是它始终忽略前导 0,可以识别所有浮点数值格式(包括十进制),但十六进制始终转换为 0,也就是parseFloat()只解析十进制格式,因此没有第二个参数的用法
// 面试题
['1', '2', '3'].map(parseInt)
// 这里其实考察两个点:map函数的参数和parseInt字符串转化
// map函数的参数是回调函数cb(currentVal[, index ,[, array]]),注意这里的index
// 所以相当与执行下面的逻辑
parseInt('1', 0) // 1, 基数为0依然按照10处理
parseInt('2', 1) // NaN, 基数1,不可能是2
parseInt('3', 2) // NaN, 基数2,不可能是有3
String
。基本概念
String类型用于表示由 0 或多个 16 位Unicode字符组成的字符序列,与 PHP 中单双引号对字符串的解释方式不同,在 ECMAScript 中,单双引号表示的字符串完全相同。
字符串字面量里可以包含转义字符(非打印字符),或其他用途的字符,当其出现在字符串中时,长度仍然作为一个字符来解析
"a \n".length; // 3
("b \u03a3"); // 'b ∑'
字符串一旦创建,并不能修改,那下面操作如何实现?
var str = "java";
str = "java" + "script";
过程:
- 首先创建一个容纳 10 个字符串的新字符串
- 在这个新字符串中填充
'java'和'script' - 销毁原来的字符串
'java'和字符串'script'
。转换为字符串
要把一个值转为字符串有两种方式。第一种使用几乎每个值都有的toString()方法,第二种是适用于任何类型的String()。
在不知道要转换的值是否为null或undefined时,可以用String():
- 如果值有
toString()方法,直接调用并返回结果 - 如果值为
null,返回'null' - 如果值为
undefined,返回'undefined'
。toString()传参
给 toString()传参,多数情况下不必传参,但是,在调用数值的toString()方法时,可以传递一个参数:输出数值的基数。默认情况下返回十进制的字符串表示
(10).toString(); // '10' ,之所以加(),因为小数点优先级高,会把10.toString看成数值而出错
(10).toString(2);// '1010'
(10).toString(8);// '12'
(10).toString(16); // 'a'
"10".toString(16); // '10',注意此处传参了,但调用toString的不是数值,原样输出
操作符
逗号操作符
。基本概念
使用逗号操作符可以在一条语句中执行多个操作,多用于声明多个变量。还用于赋值,在用于赋值时,逗号操作符总会返回表达式的最后一个:
// 声明变量
var num1 = 1,
num2 = 2,
num3 = 3;
// 赋值
var num = (5, 1, 4, 8); // num的值为8
引用数据类型
Object 类型
。基本概念
尽管ECMAScript从技术上讲是一门面向对象的语言,但不具备传统面向对象语言所支持的类和接口等结构。
对象是特定引用类型(比如Object)的实例,新对象是使用new操作符后跟一个构造函数来创建的。构造函数本身就是一个函数,只不过该函数是出于创建新对象的目的而定义的。
var person = new Object();
上面代码创建了Object引用类型的一个新实例,然后把该实例保存在变量person中,使用的构造函数Object,他只是为新对象定义了一些默认的属性和方法。ECMAScript提供了很多原生引用类型(Array、Date、RegExp、Function等),以便开发人员用以实现常见的计算任务。
var person = {
name: "jane",
home: "beijing", // 属性名可以使用字符串
66: true, // 数值属性会自动转为字符串
age: 18 // 在老的浏览器,最后一个属性后加,号,会出错
};
。当然还有字面量方式定义对象,上面例子中,左侧的{表示对象字面量的开始,因为它出现在表达式上下文中。在ECMAScript中的表达式上下文指的是能够返回一个值(表达式),赋值操作符表示后面是一个值。
一般来说,访问对象的属性使用点表示法,但还有方括号表示法,后者在通过变量访问或属性名有特殊字符、关键字或保留字时访问属性会很方便
var propertyName = "name";
person[propertyName]; // 变量
person["first name"]; // 特殊字符空格
Array 类型
.基本概念
ECMAScript中的数组和其他语言中的数组有很大差别,虽然都是有序列表,但ECMAScript中的数组的每一项可以保存任何类型的数据,而且数组大小还可动态调整。
var arr1 = new Array();
var arr2 = new Array(20); // length为20的数组(传递一项且为数值则为长度)
var arr3 = new Array("red"); // 只包含一项'red'的数组(传递一项且为非数值则为内容)
var arr4 = new Array("red", "blue");
var arr5 = Array("red", "blue"); // 还可以不用new操作符
var arr6 = ["red", "blue"];
var arr6 = [1, 2];
var arr6 = [, , ,]; // 几个逗号length便为几,值undefined
注意:数组的length属性并非只读,因此可以通过修改length属性达到扩大或裁剪数组。数组最多可以包含 4 294 967 295 个项,超出则会发生异常。
.检测数组
自从 ES3 开始,就出现了检测某个对象是不是数组的问题,对于一个网页或一个全局作用域而言,使用instanceof即可。。。但是,instanceof的问题在于,它假定单一的全局执行环境。如果网页中包含多个框架,那实际上就存在两个以上不同的全局执行环境,从而存在两个以上不同版本的 Array 构造函数,则从一个框架向另一个框架传入一个数组,那么传入的数组与在第二个框架中原生创建的数组分别具有不同的构造函数。。。
为了解决上面的问题,ES5 新增了Array.isArray()方法,而它无论在哪个全局环境下都可以检测出,某个对象到底是不是数组。
.转换数组
所有对象(指引用类型)都有toLocaleString()、toString()、valueOf()方法。
var colors = ["red", "blue", "green"];
colors.toString(); // 返回字符串,"red,blue,green"
colors.valueOf(); // 返回数组,["red", "blue", "green"]
alert(colors); // alert接收字符串参数,后台会调用toString()方法
另外toLocalestring()方法经常也返回与toString(),valueOf()方法相同的值,但也不总是如此。因为当数组调用toLocaleString()时,数组的每一项会调用自己的toLocaleString()方法,如下:
var person1 = {
toLocaleString: function() {
return "Nikolaos";
},
toString: function() {
return "Nicholas";
}
};
var person2 = {
toLocaleString: function() {
return "Grigorios";
},
toString: function() {
return "Greg";
}
};
var people = [person1, person2];
alert(people); // Nicholas,Greg
alert(people.toString()); // Nicholas,Greg
// 此处如果没有toLocaleString则调用toString(),如果都没有则返回'[object Object]'
alert(people.toLocaleString()); // Nikolaos,Grigorios
.数组转字符串
数组继承的toLocaleString()、toString()、valueof()方法,默认情况下都会返回逗号分隔的字符串,而如果使用join()方法,还可返回自定义分隔符的字符串。
如果不给join()方法传递参数,或者传入undefined,则依然是逗号分隔。如果数组中某一项是null、undefined,那么在使用toLocaleString()、toString()、valueOf()、join()方法返回的结果中以空字符串表示。
[null, undefined, "see"].join(); // ',,see'
[null, undefined, "see"].toString(); // ',,see'
[null, undefined, "see"].toLocaleString(); // ',,see'
[null, undefined, "see"].valueOf(); // 数组调用返回自身 [null, undefined, "see"]
.栈方法
ECMAScript数组也提供了一种让数组的行为类似其他数据结构的方法。比如栈,栈是一种可以限制插入和删除项的数据结构,特点是 LIFO(Last-In-First-Out),栈中项的插入(叫推入)和移除(叫弹出)只发生在一个位置–栈的顶部。
反映在数组上,也就是push()、pop()方法以便实现类似栈的行为。
var arr = [];
arr.push("red", "blue"); // 2,返回数组length
arr.pop(); // 弹出最后一项并返回,没有参数
.队列方法
栈数据结构的规则是 LIFO(后进先出),而队列则为 FIFO(First-In-First-Out),因此队列中项只发生在队列的前端。
反映在数组上,也就是unshift()、shift()方法以便实现类似队列的行为。
var arr = [];
arr.unshift("red", "blue"); // 2,返回数组length
arr.shift(); // 弹出最前面一项并返回,没有参数
.重排序方法
数组中两个已有的重排序方法reverse()、sort(),前者是反转数组,但不够灵活,因此有了sort(),默认情况下sort()是升序,在实现排序时,sort()会为每个数组项调用toString()方法,然后比较得到的字符串,以确定如何排序。即使数组项都为数值,sort()方法比较的也是字符串(也就是对应的字符编码)。二者的返回值都是排序之后的数组
var values = [0, 1, 5, 10, 15];
// 这里虽然5小于10,但进行字符串比较时,'10'则位于'5'前面
values.sort(); // [0, 1, 10, 15, 5],修改了原数组
针对上面的问题,sort()方法最好接收一个比较函数作为参数,比较函数接收两个参数,这两个参数相互比较,参数一若在参数二之前则返回负数,相等则返回 0,之后则返回正数。如果想颠倒顺序只需修改交换返回的值即可。
// compare每次都会接收values数组中的两项作为参数,进行比较
function compare(val1, val2) {
if (val1 < val1) {
return -2;
} else if (val1 > val1) {
return 2;
} else {
return 0;
}
}
var values = [0, 1, 5, 10, 15];
values.sort(compare); // [0, 1, 5, 10, 15]
我们注意到上面的compare函数内部,只是用<、>号比较,这是因为待排序的数组项有可能不是数值类型或其valueOf()没有返回数值类型,如果使用-运算符就会有问题,因此如果能确定数组项是数值型或转化后是数值型,则可以使用更加简单的比较函数,如下
"a" < "b"; // true
"a" - "b"; // NaN
// 对于数值类型或其valueOf()方法会返回数值类型的对象类型
function compare(val1, val2) {
return val1 - val2;
}
.操作方法
concat()方法,会先创建当前数组的副本(浅拷贝),然后将接收到的参数添加到副本的末尾,最后返回新数组。
slice()方法,基于当前数组的一项或多项创建新数组,有两个参数:返回项的起始位置和结束位置。只有一个参数,则至末尾所有项。两个参数的话,不包括结束位置的项。注意:不会影响原来数组,另外,若参数有负数,则用数组长度加上该数来确定相应的位置,如长度为 5 的数组调用slice(-2, -1)与调用slice(3, 4)相同,若结束位置小于起始位置,则返回空数组。
var arr = ["red", "blue", "yellow"];
arr.slice(1); // ['blue', 'yellow']
arr.slice(1, 2); // ['blue']
arr.slice(-2, -1); // ['blue'], 等价于slice(-2+3, -1+3) => slice(1, 2)
arr.slice(-1, -2); // []
arr; // ['red', 'blue', 'yellow']
splice()方法主要用途是向数组的中部插入项,因此原数组肯定也就改变了。删除操作时返回删除的项组成的数组,若没有删除则返回空数组。插入操作时,返回空数组。
- 删除,删除任意数量的项,两个参数:要删除的第一项和要删除的项数,
splice(0,2)删除前两项 - 插入,指定位置插入任意数量的项,三个参数:起始位置、要删除的项数、要插入的项。
splice(2,0,'red','green')从第二项开始,不删除,直接插入两项
var arr = ["red", "blue", "yellow"];
arr.splice(); // []
arr.splice(1, 1); // ['blue']
arr; // ['red', 'yellow']
arr.splice(-1, 0, "code", "js"); // 位置支持负数,只需加上length即可
arr; // ['red', 'code', 'js', 'yellow']
.位置方法
indexOf()、lastIndexOf()方法,两个参数:要查找的项和(可选)表示要查找起点位置的索引。前者从数组开头向后找,后者从数组末尾开始找。都返回查找的项在数组中的位置。没有找到则返回-1,匹配操作时使用===全等。
.迭代方法
ECMAScript为数组提供了 5 个迭代方法,每个方法都接收两个参数:要在每一项运行的函数和(可选的)运行该函数的作用域对象—影响this的值。传入这些方法的函数会接收三个参数:数组项的值、该项的索引和数组对象本身。
every(),给数组中每一项运行给定函数,若该函数对每一项都返回true,则返回truefilter(),给数组中每一项运行给定函数,返回该函数会返回true的项组成的数组forEach(),给数组中每一项运行给定函数,没有返回值map(),给数组中每一项运行给定函数,返回每次函数调用的结果组成的数组some(),给数组中每一项运行给定函数,若该函数对任一项返回true,则返回true
注意:以上都不会影响原数组。
.缩小方法
ECMAScript为数组提供了 2 个缩小方法:reduce()、reduceRight(),这两个方法会迭代数组的所有项,然后构建一个最终返回的值。前者从数组第一项开始迭代逐个到最后,后者从最后一项开始。两个方法都接收两个参数:在每一项上调用的函数和(可选的)作为缩小基础的初始值,传给reduce()、reduceRight()的函数接收 4 个参数:前一个值、当前值、当前项的索引和数组对象。
这个函数返回的任何值都会作为第一个参数自动传给下一项,第一次迭代发生在数组的第二项上(前提是没有给第二个参数),因此第一个参数是数组的第一项,第二个参数就是数组的第二项。
// 可以求和
var values = [1, 2, 3, 4, 5];
var sum = values.reduce((prev, cur, index, array) => {
return prev + cur;
});
// 第一次执行回调,prev是1,cur是2。第二次prev是3(1加2的结果),cur是3(数组第三项)...直到将数组中项都访问一遍
sum; // 15
// 还可以拍平数组求和,这里涉及数组判断,因此传入0,可以少判断
var arr = [2, [3, 4], [4, [5, 6]]];
var sum = arr => arr.reduce((p, c) => p + (Array.isArray(c) ? sum(c) : c), 0);
sum(arr); // 24
// 拍平数组
var flattenArr = arr =>
arr.reduce((p, c) => p.concat(Array.isArray(c) ? flattenArr(c) : c), []);
flattenArr(arr); // [2,3,4,4,5,6]
// 循环
const flatten = function(arr) {
while (arr.some(item => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
};
Date 类型
基本概念:
ECMAScript中的Date类型是在早期Java中的java.util.Date类的基础上构建的。为此,Date类型使用自UTC(Coordinated Universal Time,国际协调时间)1970 年 1 月 1 日午夜(零时)开始经过的毫秒数来保存日期。使用这种数据存储格式的条件下,Date类型保存的日期能够精确到 1970 年 1 月 1 日之前或之后的 285 616 年。
var now = new Date();
不传参数会自动获取当前日期和时间。如果想根据特定的日期和时间创建日期对象,必须传入毫秒数,为了更加简单的获取毫秒数,ECMAScript提供了Date.parse()、Date.UTC()方法。但浏览器根据地区不同,实现的有很大差异
Date.parse()接收一个表示日期的字符串,然后尝试根据字符串返回日期的毫秒数Date.UTC()同样返回毫秒数,但参数使用的分别为年份、基于 0 的月份(一月是 0)、天、小时、分钟、秒以及毫秒。年和月必须,省略天则默认为 1,其他省略则默认为 0
Date.parse(2019); // 1546300800000
Date.parse("2019 1"); // 1546272000000
new Date(Date.parse(2019)); // Tue Jan 01 2019 08:00:00 GMT+0800 (中国标准时间)
new Date(Date.parse("2019 1")); // Tue Jan 01 2019 00:00:00 GMT+0800 (中国标准时间)
Date.UTC(2019, 0); // 1546300800000 同 Date.parse(2019)
Date.UTC(2019); // 1546300800000,其实月省略后也可以
Date.UTC(2019, 1); // 1548979200000
new Date(Date.UTC(2019, 1)); //Fri Feb 01 2019 08:00:00 GMT+0800 (中国标准时间)
其实上面是通过Date.parse()获取时间戳,其实如果直接传入日期的字符串(如:new Date('May 12, 2019')),后台调用的也是Date.parse()
.Date.now
ECMAScript 5添加了Date.now()方法,返回此时的日期和时间的毫秒数。该方法简化了Date对象分析代码的工作,在不支持它的浏览器,可以使用+操作符把Date对象转为字符串已达到同样目的。
function getDate() {
console.log(Date.now()); // 1557651029232
console.log(+new Date()); // 1557651029232
}
.关于网络请求中传输Date对象的问题
正常情况下,网络请求是不能传输Date对象的。。。平时发送请求,一般都是axios等第三方库,他们拿到参数之后,遇到Date对象就会把它转为字符串,而转为字符串的过程中,就会出现问题。。。因为时间对象是时区的问题,中国是东八区时间,相比utc时间多了8个小时,如果传输的时间对象是7号0点,则axios会转为utc时间,也就是减去8个小时。。。就变成了6号,而这个6号是可以在浏览器终端看到的。
解决办法:
- 可以在给后台传输时间对象之前,将时间加上8个小时
- 最靠谱的方式是用时间戳
- 其实还可以格式为2019-09-12这种格式
.继承的方法
与其他引用类型一样,Date类型也重写了toLocaleString()、toString()、valueOf()方法,因此返回值与其他类型的也不同。
toLocaleString()会按照与浏览器设置的地区相适应的格式返回日期和时间toString()方法通常会返回带有时区信息的日期和时间valueOf()方法则根本不返回字符串,而是返回日期的毫秒数
还有一些日期/时间组件的方法,参考:日期/时间组件方法
基本包装类型
.基本概念
为了便于操作基本类型值,ECMAScript还提供了 3 个特殊的引用类型:Boolean、Number、String。和其他引用类型相似但又不同。实际上,每当读取一个基本类型值的时候,后台就会创建一个对应的基本包装类型的对象,从而让我们能够调用一些方法来操作这些数据。
var s1 = "some text";
var s2 = s1.substring(2); // "me text"
如上变量s1包含一个字符串,当然就是基本类型值,而下一行就调用了substring()方法。。。我们知道基本类型值不是对象,因而从逻辑上讲他们不应该有方法。
其实为了实现这种直观的操作,后台自动完成了一些列的处理。当第二行访问s1时,访问过程处于一种读取模式,也就是要从内存中读取这个字符串的值,而在读取模式中访问字符串时,后台会自动完成下面操作:
- 创建
String类型的一个实例(var s1 = new String('some text')) - 在实例上调用指定的方法(
var s2 = s1.substring(2)) - 销毁这个实例(
s1 = null)
经过上面的处理,基本的字符串就变得跟对象一样了,而且上面的过程也分别适用于Boolean、Number类型对应的布尔值和数字值。
引用类型与基本包装类型的主要区别就是对象的内存期。使用new操作符创建的引用类型的实例,在执行流离开当前作用域之前都一直保存在内存中。而自动创建的基本包装类型的对象,则只存在于一行代码的执行瞬间,然后立即被销毁。意味着,我们不能在运行时会基本类型添加属性或方法,如下:
var s1 = "some text";
s1.color = "red";
s1.color; // undefined
原因就是第二行创建的String对象在执行第三行代码时已经被销毁了。第三行代码又创建自己的String对象,而该对象没有color属性。
当然可以显式调用String、Boolean、Number来创建基本包装类型的对象,但最好不要这样做,因为很容易让人分不清自己处理的是基本类型还是引用类型的值。对基本包装类型的实例(用 new 构造)调用typeof会返回'object',而且所有基本包装类型的对象都会被转换为布尔值true(因为是对象了)
Object构造函数也像工厂方法一样,根据传入值的类型返回相应基本包装类型的实例。
var str = new Object("test string");
str instanceof String; // true
var num = new Object(666);
num instanceof Number; // true
var booleanVal = new Object(true);
booleanVal instanceof Boolean; // true
注意:使用new调用基本包装类型的构造函数,与直接调用同名的转型函数时不一样的。例如:
var val1 = Number("25"); // 转型函数
typeof val1; // 'number'
var val2 = new Number("25"); // 构造函数
typeof val2; // 'object'
.Boolean 类型
Boolean类型是引用类型,与基本类型布尔值不同。要创建Boolean对象,可以直接new Boolean(),可以传入true、false参数。Boolean的实例重写了valueOf()方法,返回基本类型true、false。也重写了toString()方法,返回字符串'true'、'false'。
var falseObj = new Boolean(false);
falseObj.valueOf(); // false
falseObj.toString(); // 'false'
falseObj && "look me"; // 'look me',切忌用基本包装对象的实例用在布尔表达式中
.Number 类型
与Boolean类型一样,Number类型也重写了valueOf()、toLocaleString()、toString()方法,重写后valueOf()返回基本类型值,而后两者返回字符串。
除了继承的方法之外,Number类型还提供了一些用于数值格式化为字符串的方法,如下:
// toFixed(n)方法会按照指定的小数位返回数值的字符串表示。
// n取值0~20(可能有浏览器差异)
var num = 10;
num.toFixed(2); // '10.00'
// 如果数值本身的小数位大于指定的数目,那么接近指定的最大小数位的值就会舍入
// 可能有浏览器差异
var num1 = 10.0005;
num1.toFixed(2); // '10.00'
var num2 = 10.005;
num2.toFixed(2); // '10.01'
// toExponential()方法会返回e表示法表示的数值的字符串形式。
var num3 = 102000;
num3.toExponential(); // "1.02e+5"
// 但是还有一个方法可以自动分析采用toFixed()还是toExponential()
// 也就是方法会根据传入的参数分析数值,选择更适合展示数值的方式
// toPrecision()可以表现1~21位小数(可能有浏览器差异)
var num4 = 99;
num4.toPrecision(1); // '1e+2'
num4.toPrecision(2); // '99'
num4.toPrecision(3); // '99.0'
.String 类型
String对象的方法可以在所有基本的字符串值中访问到,继承的valueOf()、toLocaleString()、toString()方法都返回对象所表示的基本字符串值。且每个实例都有length属性,String类型还提供了很多方法,用于完成对字符串的解析和操作。
1. 字符方法
两个用于访问字符串特定字符的方法:charAt()、charCodeAt(),参数都是一个基于 0 的字符位置。前者返回对应位置的字符,而后者返回字符的编码。
var str = "hello world";
str.charAt(1); // 'e'
str[1]; // 'e'
str.charCodeAt(1); // 101
2. 字符串操作方法
// concat()返回拼接后的新字符串,不影响原有字符串
var str1 = "hello";
str1.concat(" world"); // 'hello world'
str1; // 'hello'
slice()、substring()、substr()三个方法都是基于子字符串创建新字符串的方法,返回新的子字符串,都接受 1 或 2 个参数,参数一指定子字符串的开始位置,参数二表示子字符串到哪里结束(不包含)。不同的是substr()的参数二指定的是返回的字符个数,而不是位置。。。
var str2 = "hello world";
str2.slice(3); // 'lo world'
str2.substring(3); // 'lo world'
str2.substr(3); // 'lo world'
str2.slice(3, 7); // 'lo w' ,从3开始,不包含索引为7的字符
str2.substring(3, 7); // 'lo w' ,同上
str2.slice(3, 7); // 'lo worl',从3开始,共7个字符
当slice()、substring()、substr()参数里有负数时,行为就不尽相同了,其实slice()方法会将传入的负数与字符串的长度相加。substr()方法将的负的第一参数加上字符串的长度,而将负的第二个参数转换为 0。substring()则将所有负数都转换为 0。
var str3 = "hello";
str3.slice(-2); // 'lo'
str3.substr(-2); // 'lo'
str3.substring(-2); // 'hello'
str3.slice(-2, -1); // 'l', 等价于slice(3, 4)
str3.substr(-2, -1); // '', 等价于substr(3, 0)
str3.substring(-2, -1); // '', 等价于slice(0, 0)
3. 字符串位置方法
有两个从字符串中查找子字符串的方法:indexOf()、lastIndexOf(),都是从一个字符串搜索给定的子字符串,然后返回子字符串的位置,没有找到则返回-1,前者是从字符串的开头向后搜索子字符串,而后者反之。都可选第二个参数,表示索引开始的位置。
var str4 = "hello world";
str4.indexOf("o"); // 4
str4.lastIndexOf("o"); // 7
str4.indexOf("o", 5); // 7
str4.lastIndexOf("o", 8); // 7
str4.lastIndexOf("o", 1); // -1,索引的位置都是从前向后数的,即使从最后开始遍历
利用上面的特性,则可以循环获取所有匹配的项
var stringValue = "Lorem ipsum dolor sit amet, consectetur adipisicing elit";
var positions = [];
var pos = stringValue.indexOf("e");
while (pos > -1) {
positions.push(pos);
pos = stringValue.indexOf("e", pos + 1);
}
console.log(positions); // [3, 24, 32, 35, 52]
4. trim()方法
ECMAScipt 5为所有字符串定义了trim()方法,该方法会创建一个字符串的副本,并删除前置和后置的所有空格,然后返回结果。
5. 字符串大小写转换方法
ECMAScipt中涉及字符串大小写转换的方法有四个:toLowerCase()、toLocaleLowerCase()、toUpperCase()、toLocaleUpperCase(),其中toLowerCase()、toUpperCase()是两个经典的方法,借鉴自java.lang.String中的同名方法。而其他两个则是针对特定地区的实现。对有些地方,针对地区的方法和通用方法得到的结果相同,但少数语言(如土耳其语)会为Unicode大小转换应用特殊的规则,这时候就必须使用针对特定地区的方法来保证实现正确的转换。
注意:一般来说,在不知道自己的代码将在那种语言环境中运行的情况下,还是使用针对地区的方法更加稳妥一些。
6. 字符串的模式匹配方法
String类型定义了几个用于在字符串中匹配模式的方法。第一个方法就是match(),在字符串上调用这个方法,本质上与调用RegExp的exec()方法相同。match()只接受一个参数,要么是一个正则表达式,要么是一个RegExp对象。
var text = "cat, bat, sat, fat";
var pattern = /.at/;
var matches = text.match(pattern); // ["cat", index: 0, input: "cat, bat, sat, fat", groups: undefined]
matches.index; // 0
matches[0]; // "cat"
pattern.lastIndex; // 0,可以给正则表达式对象设置lastIndex,但对match方法无效,匹配总是从字符串的第一个字符开始
match()返回一个数组,第一项是与整个模式匹配的字符串,之后的每一项(如果有)保存着匹配的字符串相关的数据。index表示匹配到的字符串索引(.匹配所有字符),input则是目标字符串,groups是?
var text = "cat, bat, sat, fat";
var pattern = /.at/g; // g开启全局搜索模式,匹配到所有匹配的项
pattern.lastIndex = 2;
var matches = text.match(pattern); // ["cat", "bat", "sat", "fat"],全局模式不含index,input等信息
matches.index; // undefined
pattern.lastIndex; // 0,上面设置无效
另一个用于查找的方法是search(),参数为字符串或正则表达式,返回第一个匹配的索引,否则返回-1,始终从字符串开头查找。
为了简化替换子字符串的操作,ECMAScript提供了replalce()方法,两个参数:参数一是字符串或正则表达式,参数二可以是字符串或者一个函数。如果第一个参数是字符串,则只会替换第一个子字符串,要想替换所有的,则需要用正则,而且需要加上全局g标识。
var text = "cat, bat, sat, fat";
var result = text.replace("at", "ond");
alert(result); //"cond, bat, sat, fat"
result = text.replace(/at/g, "ond");
alert(result); //"cond, bond, sond, fond"
如果第二个参数是字符串,那么还可以使用一些特殊的字符序列,将正则表达式得到的值插入到结果字符串中。如下表:
| 变量名 | 代表的值 |
|---|---|
| $$ | 插入一个’$’ |
| $& | 插入匹配的子串 |
| $` | 插入当前匹配的子串左边的内容 |
| $’ | 插入当前匹配的子串右边的内容 |
| $n | 假如第一个参数是 RegExp 对象,并且 n 是个小于 100 的非负整数,那么插入第 n 个括号匹配的字符串。提示:索引是从 1 开始 |
var text = "cat, bat, sat, fat";
text.replace(/(.at)/g, "word ($1)");
// "word (cat), word (bat), word (sat), word (fat)"
text.replace(/(.at)/, "hello $&");
// "hello cat, bat, sat, fat"
text.replace(/(.at)/g, "hello $&");
// "hello cat, hello bat, hello sat, hello fat"
text.replace(/(.at)/, "hello $`");
// "hello , bat, sat, fat"
text.replace(/(.at)/g, "hello $`");
// "hello , hello cat, , hello cat, bat, , hello cat, bat, sat, "
text.replace(/(.at)/, "hello $'"); // 需转义,或双引号包裹
// "hello , bat, sat, fat, bat, sat, fat"
replace()方法的第二个参数也可以是一个函数,在只有一个匹配项时,会向这个函数传递 3 个参数:模式的匹配项、模式匹配项的索引和原始字符串。
如果参数一定义了多个捕获组的情况下,传递给函数的参数依次为:模式的匹配项,第一个捕获组的匹配项、第二个捕获组的匹配项……,但最后两个参数仍然分别是模式的匹配项在字符串中的位置和原始字符串。
| 变量名 | 代表的值 |
|---|---|
| match | 匹配的子串。(对应于上述的$&。) |
| p1,p2, … | 假如 replace()方法的第一个参数是一个 RegExp 对象,则代表第 n 个括号匹配的字符串。(对应于上述的$1,$2 等。)例如,如果是用 /(\a+)(\b+)/ 这个来匹配,p1 就是匹配的 \a+,p2 就是匹配的 \b+。 |
| offset | 匹配到的子字符串在原字符串中的偏移量。(比如,如果原字符串是 ‘abcd’,匹配到的子字符串是 ‘bc’,那么这个参数将会是 1) |
| string | 被匹配的原字符串。 |
function replacer(match, p1, p2, p3, offset, string) {
return [p1, p2, p3].join(" - ");
}
// [^\d]中括号里的^表示除了,这里匹配除了数字项,因此匹配到'abc'
// ()表示分组,每一组作为一个整体进行匹配,(\d*)匹配到'12345'
// 同理([^\w]*)匹配特殊字符,这里匹配到'#$*%'
var newString = "abc12345#$*%".replace(/([^\d]*)(\d*)([^\w]*)/, replacer);
console.log(newString); // abc - 12345 - #$*%
下面是一个转义HTML代码的函数:
var text = "cat, bat, sat, fat";
function htmlEscape(text) {
return text.replace(/[<>"&]/g, function(match, pos, originalText) {
switch (match) {
case "<":
return "<";
case ">":
return ">";
case "&":
return "&";
case '"':
return """;
}
});
}
htmlEscape('<p class="greeting">Hello world!</p>');
//<p class="greeting">Hello world!</p>
最后一个与模式匹配有关的方法是split()方法,该方法可以基于指定的分隔符将一个字符串分割成多个字符串,并将结果放到一个数组里。分隔符还可以是正则,还可以接受第二个参数,用于指定数组的大小。
var colorText = "red,blue,green,yellow";
var colors1 = colorText.split(",");
//["red", "blue", "green", "yellow"]
var colors2 = colorText.split(",", 2); // 指定数组长度
//["red", "blue"]
colorText.replace(/[^\,]+/g, "$"); // [$,$,$,$]
var colors3 = colorText.split(/[^\,]+/);
//["", ",", ",", ",", ""]
注意:最后一次调用split()返回的数组中,第一项和最后一项是两个空字符串,因为通过正则表达式指定的分隔符出现在了字符串的开头和末尾。
7. fromCharCode()方法
String构造函数本身有一个静态方法:fromCharCode(),接收一个或多个字符编码,然后将他们转换为字符串,其实就是charCodeAt()的逆操作。。。
String.fromCharCode(104, 101, 108, 108, 111);
// "hello"
7. 驼峰命名转换
// 下划线转换驼峰
function toHump ( name ) {
return name.replace( /\_(\w)/g, function ( all, letter ) {
return letter.toUpperCase();
} );
}
// 驼峰转换下划线
function toLine ( name ) {
return name.replace( /([A-Z])/g, "_$1" ).toLowerCase();
}
// 测试
let a = 'a_b2_345_c2345';
console.log( toHump( a ) );
let b = 'aBdaNf';
console.log( toLine( b ) );
单体内置对象
ECMA262对内置对象的定义是:“由ECMAScript实现提供的、不依赖于宿主环境的对象,这些对象在ECMAScript程序执行之前就已经存在了。”意思就是说,开发人员不必显式地实例化内置对象,因为它们已经实例化了。前面我们已经介绍了大多数内置对象,例如Object、Array和String。ECMA262 还定义了两个单体内置对象:Global和Math。
Global 对象
Global全局对象可以说是ECMAScript中最特别的一个对象了,因为不管你从什么角度上看,这个对象都是不存在的。ECMAScript 中的 Global 对象在某种意义上是作为一个终极的“兜底儿对象”来定义的。换句话说,不属于任何其他对象的属性和方法,最终都是它的属性和方法。事实上,没有全局变量或全局函数;所有在全局作用域中定义的属性和函数,都是 Global 对象的属性。前面介绍过的那些函数,诸如isNaN()、isFinite()、parseInt()以及parseFloat(),实际上全都是Global对象的方法。除此之外,Global对象还包含其他一些方法。
1. URI编码方法
Global 对象的encodeURI()和encodeURIComponent()方法可以对URI(Uniform Resource Identifiers,通用资源标识符)进行编码,以便发送给浏览器。有效的 URI 中不能包含某些字符,例如空格。而这两个 URI 编码方法就可以对 URI 进行编码,它们用特殊的 UTF8 编码替换所有无效的字符,从而让浏览器能够接受和理解。
// encodeURI()一般对整个uri进行编码,
encodeURI(";,/?:@&=+$-_.!~*'()#"); // ";,/?:@&=+$-_.!~*'()#",几乎常用的都没有被编码
encodeURI(" "); // "%20",空格被编码了
decodeURI("%20"); // " "
// encodeURIComponent()只对一段,一般是编码location.origin后面的部分
encodeURIComponent("().!~*'-_"); // "().!~*'-_"
encodeURIComponent(":/ ?&=#"); // "%3A%2F%20%3F%26%3D%23"
decodeURIComponent("%3A%2F%20%3F%26%3D%23"); // ":/ ?&=#"
2. eval()方法
大概也是整个ECMAScript语言中最强大的一个方法:eval()。eval()方法就像是一个完整的ECMAScript解析器,它只接受一个参数,即要执行的ECMAScript(或JavaScript)字符串。
eval('alert("hi")');
// 等价于
alert("hi");
当解析器发现代码中调用eval()方法时,它会将传入的参数当作实际的ECMAScript语句来解析,然后把执行结果插入到原位置。通过eval()执行的代码被认为是包含该次调用的执行环境的一部分,因此被执行的代码具有与该执行环境相同的作用域链。这意味着通过eval()执行的代码可以引用在包含环境中定义的变量,举个例子:
var msg = "hello world";
eval("alert(msg)"); // "hello world"
在 eval()中创建的任何变量或函数都不会被提升,因为在解析代码的时候,它们被包含在一个字符串中;它们只在 eval()执行的时候创建。
严格模式下,在外部访问不到 eval()中创建的任何变量或函数,因此前面的例子都会导致错误。同样,在严格模式下,为 eval 赋值也会导致错误:
"use strict"
eval = "hi"; //causes error
3. Global对象的属性
Global 对象还包含一些属性。例如,特殊的值undefined、NaN以及Infinity都是 Global 对象的属性。此外,所有原生引用类型的构造函数,像Object和Function,也都是Global对象的属性。下表列出了Global对象的所有属性。
ECMAScript5 明确禁止给undefined、NaN和Infinity赋值,这样做即使在非严格模式下也会导致错误。
4. Global对象的属性
ECMAScript虽然没有指出如何直接访问 Global 对象,但Web 浏览器都是将这个全局对象作为 window 对象的一部分加以实现的。因此,在全局作用域中声明的所有变量和函数,就都成为了 window 对象的属性。来看下面的例子。
JavaScript 中的window 对象除了扮演 ECMAScript 规定的 Global 对象的角色外,还承担了很多别的任务。
Math 对象
ECMAScript还为保存数学公式和信息提供了一个公共位置,即Math对象。与我们在JavaScript直接编写的计算功能相比,Math对象提供的计算功能执行起来要快得多。
1. Math.max()和Math.min()
前者用于确定一组数值中最大值,后者确定最小值,都接收任意多个值。但注意,接收的都是具体的数值,而非对象类型(比如数组)
var max = Math.max(1, 2, 5, 10); // 10
var min = Math.min(1, 2, 5, 10); // 1
但有时确实想获取一个数组中的最大或最小值呢?可以如下:
// apply参数一设置this,参数二正好为数组
var max = Math.max.apply(Math, [1, 2, 5, 10]); // 10
// 利用展开语法
var min = Math.min(...[1, 2, 5, 10]); // 1
总结:其实遇到类似场景,都可以换个角度,能不能利用别的什么扩展方法来实现,比如上面的apply
2. 舍入方法Math.ceil()、Math.floor()、Math.round()
Math.ceil()执行向上舍入Math.floor()执行向下舍入Math.round()执行标准舍入,也就是四舍五入
Math.ceil(25.9); // 26
Math.ceil(25.5); // 26
Math.ceil(25.1); // 26
Math.floor(25.9); // 25
Math.floor(25.5); // 25
Math.floor(25.1); // 25
Math.round(25.9); // 26
Math.round(25.5); // 26
Math.round(25.1); // 25
3. 随机数方法Math.random()
该方法返回 0~1 之间(不包括 0 和 1)的随机数,而且精度是小数点为后 17 位(也就是浮点数精度)。还可以配合舍入方法,生成指定的几到几的数值
Math.random(); // 0.8441821044639932,小数点后17位
Math.floor(Math.random() * 10 + 1); // 1到10之间的数,包含1和10
Math.floor(Math.random() * 9 + 2); // 2到10之间的数,包含2和10
// 总结规律,可以封装以下代码
function selectFrom(lowerValue, upperValue) {
var choices = upperValue - lowerValue + 1;
return Math.floor(Math.random() * choices + lowerValue);
}
var num = selectFrom(2, 10);
alert(num); //number between 2 and 10
随机数函数常用在抽奖中,可以灵活使用。当然还有其他的一些方法,比如求绝对值的Math.abs()
原始类型与引用类型对比
- 原始类型具有不可变性,每次操作(如字符串操作)都是在栈中重新开辟空间
- 原始类型相互之间比较的是栈中的值,而引用类型比较的是存在栈中的地址
- 访问变量有按值和按引用两种方式,但参数传递只能按值传递
面向对象的程序设计
理解对象属性
面向对象(ObjectOriented,OO)的语言有一个标志,那就是它们都有类的概念,而通过类可以创建任意多个具有相同属性和方法的对象。前面提到过,ECMAScript中没有类的概念,因此它的对象也与基于类的语言中的对象有所不同。
ECMA262 把对象定义为:“无序属性的集合,其属性可以包含基本值、对象或者函数。,我们可以把 ECMAScript 的对象想象成散列表:无非就是一组名值对,其中值可以是数据或函数。
早期我们创建自定义对象的方式是创建Object实例:
var person = new Object();
person.name = "Nicholas";
person.age = 29;
person.job = "Software Engineer";
person.sayName = function() {
alert(this.name);
};
person.sayName();
后来,我们通过对象字面量方式创建:
var person = {
name : "Nicholas",
age : 29,
job : "Software Engineer",
sayName : function(){
alert(this.name);
};
};
person.sayName();
这两种方式定义的对象相同,具有相同的属性和方法。但这些属性在创建时,其实都自动带有一些特征值(characteristic),而 js 正是通过这些特征值来定义他们的行为。
属性类型
ECMA262 第 5 版在定义只有内部才用的特性(attribute)时,描述了属性(property)的各种特征。ECMA262定义这些特性是为了实现 JavaScript 引擎用的,因此在 JavaScript 中不能直接访问它们。为了表示特性是内部值,该规范把它们放在了两对儿方括号中,例如[[Enumerable]]。尽管 ECMA262 第 3 版的定义有些不同,
ECMAScript 中有两种属性:数据属性和访问器属性。
数据属性:
[[Configurable]],表示能否使用 delete 删除属性、能否修改属性的特性或者能否把属性修改为访问器属性。[[Enumerable]],表示能否使用 for-in 遍历属性[[Writable]],表示能否修改属性的值[[Value]],表示这个属性的数据值。默认为undefined
前三个当自定义对象时,默认都为true。当然可以通过用ECMAScript5的Object.defineProperty()方法来修改默认的特性。这个方法接收三个参数:属性所在的对象、属性的名字和一个描述符对象。其中,描述符(descriptor)对象的属性必须是:configurable、enumerable、writable和value。设置其中的一或多个值,可以修改对应的特性值。例如:
var person = Object.create(null); // 这样创建的空对象更纯
// 控制台可以直接查看 {} 与 person ,后者没有原型上的属性或方法,
// 直接字面量{} 和 new Object()继承的属性相同
Object.defineProperty(person, "name", {
writable: false, // 不可写
value: "joan"
});
person.name; // 'joan'
person.name = "changed"; // 尝试修改
person.name; // 'joan',
上面操作表示 name 为只读的,不可修改。非严格模式下修改,会忽略。严格模式下回报错。同样,也适用不可配置的属性,如下
var person = Object.create(null); // 这样创建的空对象更纯
Object.defineProperty(person, "name", {
configurable: false, // 不可配置
value: "joan"
});
person.name; // 'joan'
delete person.name; // 尝试删除
person.name; // 'joan',
但需要注意,一旦configurable设置为 false,就不能再把它变成可配置的了,也就是再次调用Object.defineProperty()修改除writable以外的特性都会报错。。。
var person = Object.create(null);
Object.defineProperty(person, "name", {
configurable: false, // 不可配置
value: "joan"
});
// error : Cannot redefine property: name
Object.defineProperty(person, "name", {
configurable: true, // 再次尝试修改,报错,无法重复定义
value: "joan"
});
注意:在调用Object.defineProperty()方法时,如果不指定,configurable、enumerable和writable特性的默认值都是false。而如果自定创建对象的话,则都默认为true。
访问器属性:
访问器属性不包含数据值;它们包含一对儿 getter 和 setter 函数(不过,这两个函数都不是必需的)。在读取访问器属性时,会调用 getter 函数,这个函数负责返回有效的值;在写入访问器属性时,会调用 setter 函数并传入新值,访问器属性有如下 4 个特性。
[[Configurable]],表示能否使用 delete 删除属性、能否修改属性的特性或者能否把属性修改为数据属性。[[Enumerable]],表示能否使用 for-in 遍历属性[[Get]],在读取属性时调用的函数,默认为undefined[[Set]],在写入属性时调用的函数。默认为undefined
var book = {
_year: 2004,
edition: 1
};
// 注意虽然上面定义的是_year,但这里设置的year
// 这里如果定义_year,则会堆栈溢出,因为每次设置都会触发监听
// 而这里的方式,其实是设置一个属性的值会导致其他属性发生变化
Object.defineProperty(book, "year", {
get: function() {
return this._year;
},
set: function(newVal) {
if (newVal > 2004) {
this._year = newVal;
this.edition += newVal - 2004;
}
}
});
book.year = 2005;
book.edition; // 2
注意:,以上代码创建了一个 book 对象,并给它定义两个默认的属性:_year 和 edition。_year 前面的下划线是一种常用的记号,用于表示只能通过对象方法访问的属性。而访问器属性 year则包含一个 getter 函数和一个 setter 函数。getter 函数返回_year 的值,setter 函数通过计算来确定正确的版本。因此,把 year 属性修改为 2005 会导致_year 变成 2005,而 edition 变为 2。
上面也是使用访问器属性常用的方式,即设置一个属性的值会导致其他属性发生变化。vue老版本的双向数据绑定就基于此。
不一定非要同时指定getter和setter,只指定getter意味着属性不能写,尝试写入属性会被忽略,严格模式下,会报错。只指定setter意味着属性不能读,尝试读则返回undefined。
定义多个属性
由于经常一次性给对象定义多个属性,因此可以用Object.defineProperties()方法实现。两个参数:参数一为要定义的对象,参数二的对象的属性与第一个对象中要添加或修改的属性一一对应,如下:
var book = {};
Object.defineProperties(book, {
_year: {
value: 2004;
},
edition: {
value: 1
},
year: {
get: function(){
return this._year
},
set: function(newVal){
if(newVal > 2004){
this._year = newVal;
this.edition += newVal -2004;
}
}
}
})
以上代码在 book 对外上定义了两个数据属性(_year和edition)和一个访问器属性(year)。最终的对象与上面定义的对象相同。
读取属性的特性
Object.getOwnPropertyDescriptor()获取给定属性的描述符,
Object.getOwnPropertyDescriptor(book, "_year");
// value: 2004,
// writable: true,
// enumerable: true,
// configurable: true
Object.getOwnPropertyDescriptor(book, "year");
// configurable: false,
// enumerable: false,
// get: ƒ (){},
// set: ƒ (newVal){}
创建对象
虽然Object构造函数或对象字面量都可以用来创建单个对象,但这些方式有个明显的缺点:使用同一个接口创建很多对象,会产生大量的重复代码。为解决这个问题,人们开始使用工厂模式的一种变体。
工厂模式
工厂模式是软件工程领域一种广为人知的设计模式,这种模式抽象了创建具体对象的过程。考虑到在ECMAScript 中无法创建类,开发人员就发明了一种函数,用函数来封装以特定接口创建对象的细节,如:
function createPerson(name, age, job) {
var o = new Object();
o.name = name;
o.age = age;
o.job = job;
o.sayName = function() {
alert(this.name);
};
return o;
}
var person1 = createPerson("Nicholas", 29, "Software Engineer");
var person2 = createPerson("Greg", 27, "Doctor");
person1.sayName(); //"Nicholas"
person2.sayName(); //"Greg"
工厂模式虽然解决了创建多个相似对象的问题,但却没有解决对象识别的问题(即怎样知道一个对象的类型)
构造函数模式
ECMAScript中的构造函数可以用来创建特定类型的对象,比如像Object和Array这样的原生构造函数。当然还可以自己定义构造函数,比如:
function Person(name, age, job) {
this.name = name;
this.age = age;
this.job = job;
this.sayName = function() {
alert(this.name);
};
}
var person1 = new Person("Nicholas", 29, "Software Engineer");
var person2 = new Person("Greg", 27, "Doctor");
person1.sayName(); //"Nicholas"
person2.sayName(); //"Greg"
alert(person1.sayName == person2.sayName); //false
上面代码中,Person()函数取代了createPerson()函数。但他们还有以下不同之处:
- 没有显式创建对象
- 直接将属性和方法赋值给 this 对象
- 没有 return 语句
此外函数名Person使用的是大写字母 P。这个做法借鉴自其他 OO 语言,主要是为了区别于 ECMAScript 中的其他函数;因为构造函数本身也是函数,只不过可以用来创建对象而已。
要创建Person的新实例,必须使用new操作符,以这种方式调用构造函数实际上会经历以下 4 个步骤:
- 创建一个对象
- 将构造函数的作用域赋给新对象(因此 this 就指向了这个新对象);
- 执行构造函数中的代码(为这个新对象添加属性);
- 返回新对象。
在前面代码中,person1 和 person2 分别保存着 Person 的一个不同的实例。这两个对象都有一个 constructor(构造函数)属性,该属性指向 Person,如下所示。
alert(person1.constructor == Person); //true
alert(person2.constructor == Person); //true
注意:对象的constructor 属性最初是用来标识对象类型的,比如这里对象类型就是Person。而不像原生构造函数构造出来的全是Object类型没法区分。当然他们也都是Object类型,如下:
alert(person1 instanceof Object); //true
alert(person1 instanceof Person); //true
alert(person2 instanceof Object); //true
alert(person2 instanceof Person); //true
创建自定义的构造函数(如此处的 Person)意味着将来可以将它的实例标识为一种特定的类型;而这正是构造函数模式胜过工厂模式的地方。
构造函数的问题
构造函数模式虽然好用,但使用构造函数时每个方法都要在每个实例上重新创建一遍。如上面person1、person2都有一个同名sayName()方法,但那两个方法不是同一个Function实例。因为函数也是对象,因此每次定一个函数,也就是实例化一个对象。。。因此也可以如下定义:
function Person(name, age, job) {
this.name = name;
this.age = age;
this.job = job;
this.sayName = new Function("alert(this.name)");
// this.sayName = function(){
// alert(this.name);
// };
}
var p1 = new Person("a", 17, "aa");
var p2 = new Person("b", 18, "bb");
p1.sayName === p2.sayName; // false
从这个角度看构造函数,更容易明白每个 Person 实例都包含一个不同的Function实例(以显示 name 属性)的本质。说明白些,以这种方式创建函数,会导致不同的作用域链和标识符解析,但创建 Function 新实例的机制仍然是相同的。然而创建两个完成同样任务Function实例的确没有必要。况且有 this 对象在,根本不用在执行代码前就把函数绑定到特定对象上面。因此可以如下:
function Person(name, age, job) {
this.name = name;
this.age = age;
this.job = job;
this.sayName = sayName;
}
function sayName() {
alert(this.name);
}
var p1 = new Person("a", 17, "aa");
var p2 = new Person("b", 18, "bb");
p1.sayName === p2.sayName; // true
这样一来,由于sayName包含的是一个指向函数的指针,因此person1和person2对象就共享了在全局作用域中定义的同一个sayName()函数。这样做确实解决了两个函数做同一件事的问题,但会有全局变量污染的问题。。。
原型模式
我们创建的每个函数都有一个prototype(原型)属性,这个属性是一个指针,指向一个对象,而这个对象的用途是包含可以由特定类型的所有实例共享的属性和方法。使用原型对象的好处是可以让所有对象实例共享它所包含的属性和方法。
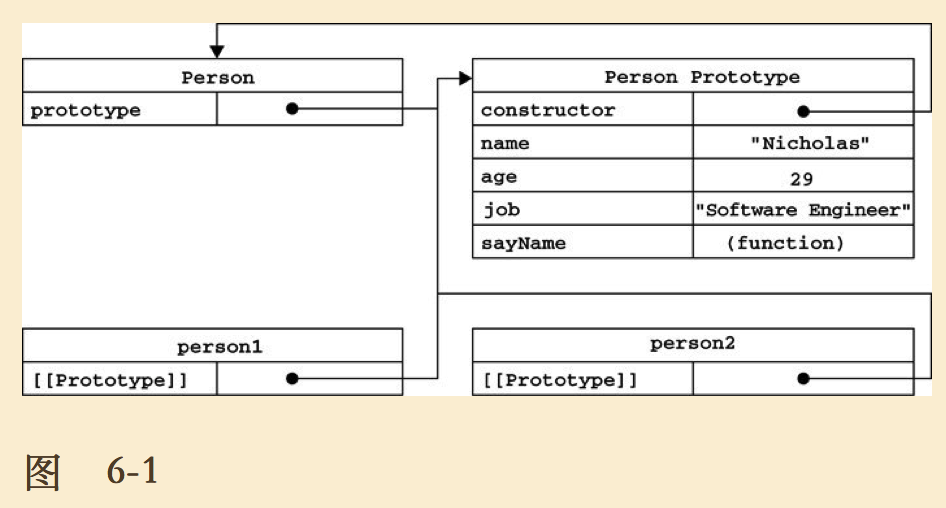
创建了自定义的构造函数之后,其原型对象默认只会取得constructor属性;至于其他方法,则都是从Object继承而来的。当调用构造函数创建一个新实例后,该实例的内部将包含一个指针(内部属性),指向构造函数的原型对象。ECMA262 第 5 版中管这个指针叫[[Prototype]]。虽然在脚本中没有标准的方式访问[[Prototype]],但Firefox、Safari和Chrome在每个对象上都支持一个属性__proto__。
虽然在所有实现中都无法访问到[[Prototype]],但可以通过isPrototypeOf()方法来确定对象之间是否存在这种关系。
// p1,p2内部都有一个指针指向Person.prototype
Person.prototype.isPrototypeOf(p1); // true
Person.prototype.isPrototypeOf(p2); // true
ECMAScript 5新增方法Object.getPrototypeOf(),可以返回[[Prototype]]的值。
Object.getPrototypeOf(p1) === Person.prototype; // true
虽然可以通过实例对象访问原型中的值,但却不能通过对象实例重写原型中的值。我们在实例中增加的同名属性或方法只是屏蔽了原型中的那个属性或方法(和属性查找规则有关)。
即使将这个属性设置为null,也只会在实例中设置这个属性,而不会恢复其指向原型的连接。不过,使用delete操作符则可以完全删除实例属性,从而让我们能够重新访问原型中的属性。
使用hasOwnProperty()方法可以检测一个属性是存在于实例中,还是存在于原型中,这个方法(不要忘了它是从 Object 继承来的)只在给定属性存在于对象实例中时,才会返回 true。。而in和for-in操作都可以遍历对象及原型上的属性。配合hasOwnProperty()可以只遍历对象或原型上的属性和方法。
如果你想要得到所有实例属性,无论它是否可枚举,都可以使用Object.getOwnPropertyNames()方法。
Object.getOwnPropertyNames(p1.__proto__); // ["constructor"]
Object.getOwnPropertyNames(Person.prototype); // ["constructor"]
原型语法
function Person() {}
Person.prototype = {
name: "joan",
age: 17,
sayName: function() {
alert(this.name);
}
};
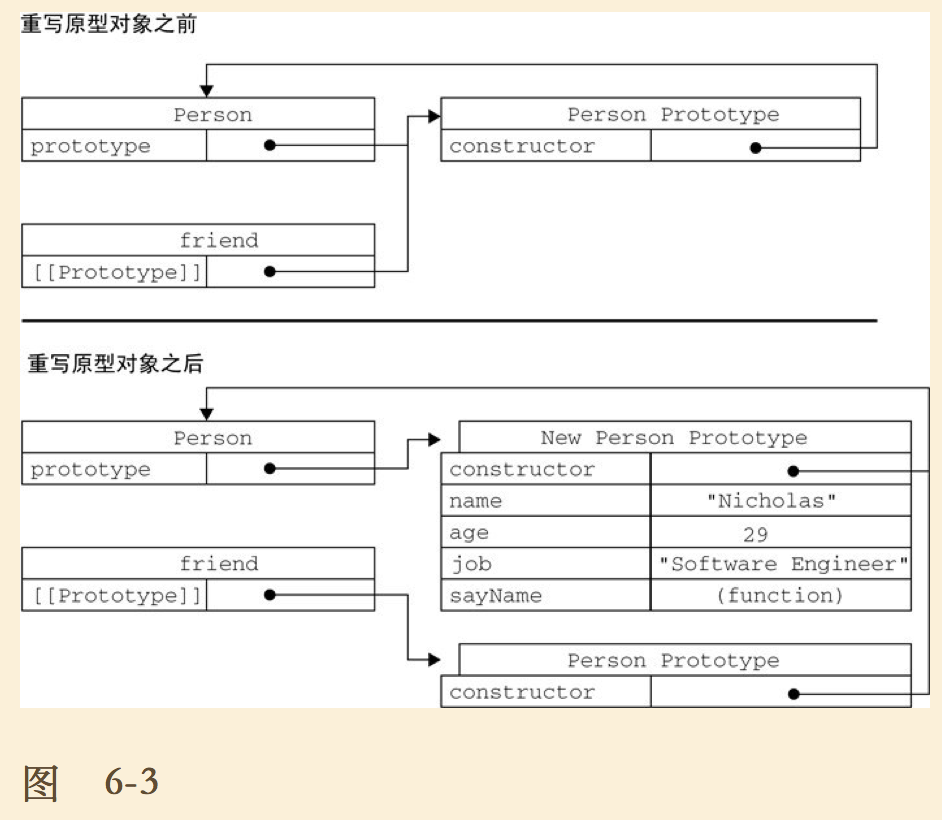
在上面的代码中,我们将Person.prototype设置为等于一个以对象字面量形式创建的新对象。最终结果相同,但有一个例外:constructor属性不再指向Person了,因为我们这里相当于重写了默认的prototype对象。
var p = new Person();
p instanceof Object; // true
p instanceof Person; // true
p.constructor === Object; // true
p.constructor === Person; // false
如上,最后一行为false,因为constrctor最初就是用来表示对象类型的,如果都指向了Object,那也就没有意义了。。。因此可以如下修改:
function Person() {}
Person.prototype = {
// 增加下面一行
constructor: Person
};
但是这样有个问题,以这种方式重设constructor属性会导致它的[[Enumerable]]特性被设置为true。默认情况下,原生的 constructor 属性是不可枚举的,因此如果你使用兼容ECMAScript5的JavaScript引擎,可以使用Object.defineProperty()
function Person() {}
Person.prototype = {
// ...
};
Object.defineProperty(Person.prototype, "constructor", {
enumerable: false,
value: Person
});
以下是整个创建对象的历史进程:
// 创建对象发展历程
// 发展历程一
// 直接新建Object实例,然后挂载属性和方法
var person = new Object();
person.name = "Nicholas";
person.age = 29;
person.job = "Software Engineer";
person.sayName = function() {
alert(this.name);
};
person.sayName();
// 发展历程二
// 对象字面量模式
var person = {
name: "Nicholas",
age: 29,
job: "Software Engineer",
sayName: function() {
alert(this.name);
}
};
// -------数据属性和访问器属性---------
// 数据属性
var person = {};
Object.defineProperty(person, "name", {
configurable: false, // 不可删除
value: "Nicholas"
});
console.log(person.name); // "Nicholas"
delete person.name;
console.log(person.name); // "Nicholas"
// ----------------------------------
// 访问器属性
var book = {
_year: 2004,
edition: 1
};
Object.defineProperty(book, "year", {
get: function() {
return this._year;
},
set: function(newValue) {
if (newValue > 2004) {
this._year = newValue;
this.edition += newValue - 2004;
}
}
});
book.year = 2005;
alert(book.edition); //2
// 同时定义多个属性
var book = {};
Object.defineProperties(book, {
_year: {
value: 2004
},
edition: {
value: 1
},
year: {
get: function() {
return this._year;
},
set: function(newValue) {
if (newValue > 2004) {
this._year = newValue;
this.edition += newValue - 2004;
}
}
}
});
book.year = 2005;
// alert(book.edition); //2
// 读取数据属性的特性
Object.getOwnPropertyDescriptor(book, "_year");
// {value: 2004, writable: false, enumerable: false, configurable: false}
// 读取访问器属性的特性
Object.getOwnPropertyDescriptor(book, "year");
// {get: ƒ, set: ƒ, enumerable: false, configurable: false}
// 发展历程三
// Object构造函数和对象字面量方式缺点,每次都产生大量重复的代码
// 工厂模式
function createPerson(name, age, job) {
// 注意三点:新建Object对象,挂载,返回新创建的对象
var o = new Object();
o.name = name;
o.age = age;
o.job = job;
o.sayName = function() {
alert(this.name);
};
return o;
}
var person1 = createPerson("Nicholas", 29, "Software Engineer");
var person2 = createPerson("Greg", 27, "Doctor");
person1.sayName(); //"Nicholas"
person2.sayName(); //"Greg"
// 发展历程四
// 工厂模式解决了创建多个相似对象的问题,
// 但没有解决新创建的对象属于哪一类的问题
// 构造函数模式
function Person(name, age, job) {
// 注意三点:没有显式创建对象,直接将属性和方法赋值给this对象,没有return语句
this.name = name;
this.age = age;
this.job = job;
this.sayName = function() {
alert(this.name);
};
}
// 创建Person实例需要用new
// 1. 创建一个对象
// 2. 将构造函数的作用域赋给新对象(this就指向新对象)
// 3. 执行构造函数中的代码(为新对象添加属性)
// 4. 返回新对象
var person1 = new Person("Nicholas", 29, "Software Engineer");
var person2 = new Person("Greg", 27, "Doctor");
person1.sayName(); //"Nicholas"
person2.sayName(); //"Greg"
// 用instanceof检测对象类型
alert(person1 instanceof Object); //true
alert(person1 instanceof Person); //true
alert(person2 instanceof Object); //true
alert(person2 instanceof Person); //true
// constructor属性最初就是用来标识对象类型的,比如此处的Person
// 创建自定义的构造函数意味着将来可以将它的实例标示为一种特定的类型
// 而这正是构造函数胜过工厂模式的地方
alert(person1.constructor == Person); //true
alert(person2.constructor == Person); //true
// 构造函数与其他函数的唯一区别,就在于调用它们的方式不同。
// 不过,构造函数毕竟也是函数,不存在定义构造函数的特殊语法。
// 任何函数,只要通过new操作符来调用,那它就可以作为构造函数;
// 而任何函数,如果不通过new操作符来调用,那它跟普通函数也不会有什么两样。
// 构造函数的问题
// 缺点:每个方法都要在实例上重新创建一遍,因为函数也是对象,因此相当于每次都实例化一个
// 和下面等价
function Person(name, age, job) {
this.name = name;
this.age = age;
this.job = job;
this.sayName = new Function("alert(this.name)");
}
// 可以这样定义,以解决问题,但有全局污染的问题
function Person(name, age, job) {
this.name = name;
this.age = age;
this.job = job;
this.sayName = sayName;
}
function sayName() {
alert(this.name);
}
var person1 = new Person("Nicholas", 29, "Software Engineer");
var person2 = new Person("Greg", 27, "Doctor");
alert(person1.sayName == person2.sayName); //true
// 发展历程五
// 构造函数模式的问题,如上,为了解决这个问题,可以通过原型模式
// 原型模式
function Person() {}
// 我们创建的每个函数都有一个prototype(原型)属性,指向一个对象
// 而这个对象的用途就是包含特定类型的所有实例共享的属性和方法
Person.prototype.name = "Nicholas";
Person.prototype.age = 29;
Person.prototype.job = "Software Engineer";
Person.prototype.sayName = function() {
alert(this.name);
};
var person1 = new Person();
person1.sayName(); //"Nicholas"
var person2 = new Person();
person2.sayName(); //"Nicholas"
// 新对象具有相同的属性和方法
alert(person1.sayName == person2.sayName); //true
// 可以通过isPrototypeOf来确定原型与实例是否有关系
alert(Person.prototype.isPrototypeOf(person1)); //true
alert(Person.prototype.isPrototypeOf(person2)); //true
// ES 5新增方法Object.getPrototypeOf(),返回原型
//only works if Object.getPrototypeOf() is available
if (Object.getPrototypeOf) {
alert(Object.getPrototypeOf(person1) == Person.prototype); //true
alert(Object.getPrototypeOf(person1).name); //"Nicholas"
}
// 每当代码读取某个对象的某个属性时,都会执行一次搜索,目标是具有给定名字的属性。
// 搜索首先从对象实例本身开始。如果在实例中找到了具有给定名字的属性,则返回该属性的值;
// 如果没有找到,则继续搜索指针指向的原型对象,在原型对象中查找具有给定名字的属性。
// 如果在原型对象中找到了这个属性,则返回该属性的值。
// 不能通过对象实例重写原型中的值。实例中同名属性只是会屏蔽原型中的那个属性而已。
// 即使设置为null,但delete后,就可以再找到原型上的属性了
// hasOwnProperty()方法检测一个属性是否在实例还是原型中,
// 只在给定属性存在于对象实例中才返回true
// hasOwnProperty()方法继承之Object
// in操作符和for-in都可以遍历实例和原型中可枚举的属性和方法
// 如果实例中的属性和方法屏蔽了原型中的同名属性或方法,则可以遍历出,如下
var o = {
toString: function() {
return "My Object";
}
};
Object.defineProperty(o, "_name", {
value: "private",
enumerable: false
});
for (var prop in o) {
console.log(prop); // toString
}
// 要想取得所有实例属性,无论是否可枚举,可以用Object.getOwnPropertyNames()
Object.getOwnPropertyNames(o);
// ["toString", "_name"]
// 发展历程六
// 原型模式模式的问题,有点啰嗦,每次都得写Person.prototype
// 更简单的原型语法
function Person() {}
Person.prototype = {
name: "Nicholas",
age: 29,
job: "Software Engineer",
sayName: function() {
alert(this.name);
}
};
var friend = new Person();
alert(friend instanceof Object); //true
alert(friend instanceof Person); //true
// 注意,此处重写了Person.prototype,导致constructor属性不再指向Person了。
alert(friend.constructor == Person); //false
alert(friend.constructor == Object); //true
// 分析:
// 每创建一个函数,就会同时创建它的prototype对象,这个对象也会自动获得constructor属性。
// 而我们在这里使用的语法,本质上完全重写了默认的prototype对象,
// 因此constructor属性也就变成了新对象的constructor属性(指向Object构造函数),不再指向Person函数。
// 此时,尽管instanceof操作符还能返回正确的结果,但通过constructor已经无法确定对象的类型了,
// 因此如果很需要对象类型的标识,可以增加如下
Person.prototype = {
// 注意,这样会导致原型的constructor可枚举,默认是不可枚举的
constructor: Person
};
// 因此可以如下
Object.defineProperty(Person.prototype, "constructor", {
enumerable: false,
value: Person
});
// 原型的动态性
// 尽管可以随时为原型添加属性和方法,并且修改能够立即在所有对象实例中反映出来,
// 但如果是重写整个原型对象,结果就会发生变化
// 调用构造函数时会为实例添加一个指向最初原型的[[Prototype]]指针,
// 而把原型修改为另外一个对象就等于切断了构造函数与最初原型之间的联系。
function Person() {}
var friend = new Person();
Person.prototype = {
constructor: Person,
name: "Nicholas",
age: 29,
job: "Software Engineer",
sayName: function() {
alert(this.name);
}
};
friend.sayName(); //error
// 因为friend指向的原型中不包含以该名字命名的属性。
// 重写原型对象切断了现有原型与任何之前已经存在的对象实例之间的联系;
// 而已经存在的对象实例引用的仍然是最初的原型。
// 具体原因参考6-3图片
// 发展历程六的问题
// 更简单的原型语法虽然写着简单了,但是本质的共享问题依然存在
// 如果只是共享基本数据类型和方法倒也还行,但是如果共享引用数据类型则不好
function Person() {}
Person.prototype = {
constructor: Person,
name: "Nicholas",
age: 29,
job: "Software Engineer",
friends: ["Shelby", "Court"],
sayName: function() {
alert(this.name);
}
};
var person1 = new Person();
var person2 = new Person();
person1.name = "I am person1";
person1.friends.push("Van");
// 基本类型都是新开辟空间
alert(person1.name); // "I am person1"
alert(person2.name); // "Nicholas"
// 注意因为是引用类型,则指向相同。
alert(person1.friends); //"Shelby,Court,Van"
alert(person2.friends); //"Shelby,Court,Van"
alert(person1.friends === person2.friends); //true
alert(person1.sayName === person2.sayName); //true
// 发展历程七
// 原型模式的问题如上,可以组合使用使用构造函数模式和原型模式
// 构造函数与原型组合模式(目前最佳模式)
function Person(name, age, job) {
this.name = name;
this.age = age;
this.job = job;
this.friends = ["Shelby", "Court"];
}
Person.prototype = {
constructor: Person,
sayName: function() {
alert(this.name);
}
};
var person1 = new Person("Nicholas", 29, "Software Engineer");
var person2 = new Person("Greg", 27, "Doctor");
person1.friends.push("Van");
alert(person1.friends); //"Shelby,Court,Van"
alert(person2.friends); //"Shelby,Court"
alert(person1.friends === person2.friends); //false
alert(person1.sayName === person2.sayName); //true
// 后续发展:动态原型模式
// 该模式有条件的初始化原型上的方法,而且都写在了构造函数里
function Person(name, age, job) {
//properties
this.name = name;
this.age = age;
this.job = job;
//methods
if (typeof this.sayName !== "function") {
Person.prototype.sayName = function() {
alert(this.name);
};
}
}
var friend = new Person("Nicholas", 29, "Software Engineer");
friend.sayName();
// 注意,仍然不要重写原型,理由前面说过
// 后续发展:寄生构造函数模式
// 思想:创建一个函数,封装创建的对象,返回创建的对象
function Person(name, age, job) {
var o = new Object();
o.name = name;
o.age = age;
o.job = job;
o.sayName = function() {
alert(this.name);
};
return o;
}
var friend = new Person("Nicholas", 29, "Software Engineer");
friend.sayName(); //"Nicholas"
// 除了使用new操作符并把使用的包装函数叫做构造函数之外,
// 这个模式跟工厂模式其实是一模一样的。
// 构造函数在不返回值的情况下,默认会返回新对象实例。
// 而通过在构造函数的末尾添加一个return语句,可以重写调用构造函数时返回的值。
// 这个模式可以在特殊的情况下用来为对象创建构造函数。
// 假设我们想创建一个具有额外方法的特殊数组。
// 由于不能直接修改Array构造函数,因此可以使用这个模式。如下:
function SpecialArray() {
//create the array
var values = new Array();
//add the values
values.push.apply(values, arguments);
//assign the method
values.toPipedString = function() {
return this.join("|");
};
//return it
return values;
}
var colors = new SpecialArray("red", "blue", "green");
alert(colors.toPipedString()); // "red|blue|green"
alert(colors instanceof SpecialArray);
// 在这个函数内部,首先创建了一个数组,
// 然后push()方法(用构造函数接收到的所有参数)初始化了数组的值。
// 随后,又给数组实例添加了一个toPipedString()方法,该方法返回以竖线分割的数组值。
// 最后,将数组以函数值的形式返回。
// 注意:返回的对象与构造函数或者与构造函数的原型属性之间没有关系;
理解继承
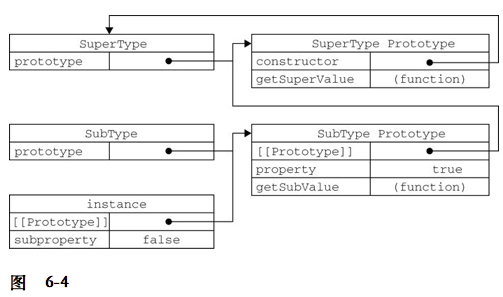
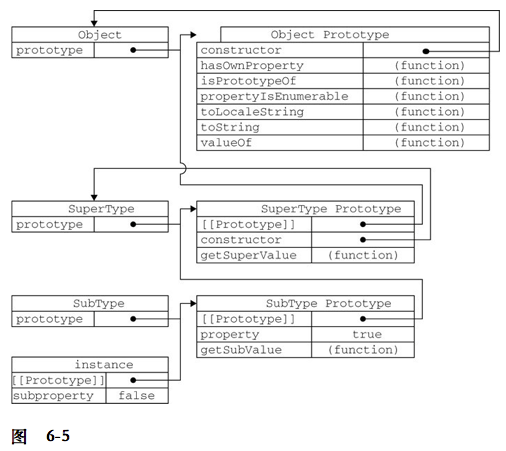
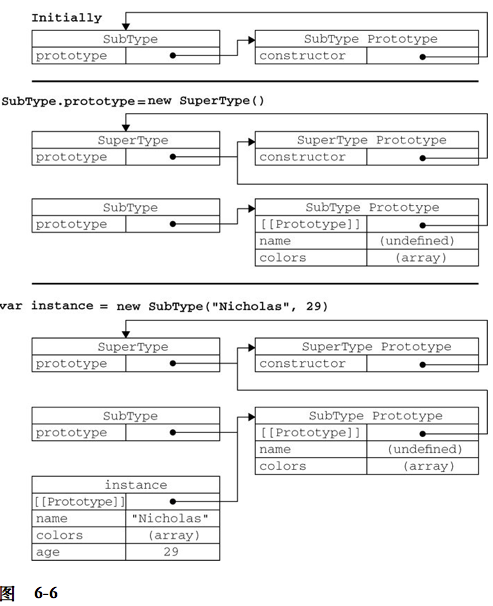
// 继承的发展历程
// -----继承概念-----:
// 继承是OO语言中的一个最为人津津乐道的概念。
// 许多OO语言都支持两种继承方式:接口继承和实现继承。
// 接口继承只继承方法签名,而实现继承则继承实际的方法。
// 由于函数没有签名,在ECMAScript中无法实现接口继承。
// ECMAScript只支持实现继承,而且其实现继承主要是依靠原型链来实现的
// -----基本模式-----:
// 具体过程参考图6-4
function SuperType() {
this.property = true;
}
SuperType.prototype.getSuperValue = function() {
return this.property;
};
function SubType() {
this.subproperty = false;
}
//inherit from SuperType
SubType.prototype = new SuperType();
// 务必注意,给原型添加方法的代码一定要放在替换原型的语句之后
SubType.prototype.getSubValue = function() {
return this.subproperty;
};
var instance = new SubType();
// 分析过程
// 1. 先画出SuperType与SuperType.prototyp的关系图
// 2. 再画出SubType与SubType.prototype的关系图,
// 注意此时SubType.prototype是SuperType的实例,因此会继承来自SuperType及其原型的属性和方法,因为是实例,因此会有[[prototype]]
// 3. 由于原型的动态性,再在SubType.prototype上增加getSubValue方法
// 4. 再实例化SubType,则会直接继承subproperty属性,
// 通过__proto__可以访问property和getSubValue,
// 通过__proto__.__proto__可以访问getSuperValue
console.log(instance.subproperty); // false
console.log(instance.property); // true
console.log(instance.getSuperValue()); //true
// 我们可以说instance是Object、SuperType或SubType中任何一个类型的实例
console.log(instance instanceof Object); //true
console.log(instance instanceof SuperType); //true
console.log(instance instanceof SubType); //true
// 还可以
console.log(Object.prototype.isPrototypeOf(instance)); //true
console.log(SuperType.prototype.isPrototypeOf(instance)); //true
console.log(SubType.prototype.isPrototypeOf(instance)); //true
// 注意,此时instance.constructor(实例访问原型对象上属性)指向了SuperType,具体参考图6-4
// -----顶端的默认原型-----:
// 所有引用类型默认都继承Object
// 务必记住:所有函数的默认原型都是Object的实例,而函数的默认原型都含有[[prototype]]
// 这也是为何自定义类型都会继承toString(),valueOf()等。
// 完整关系图参考6-5
// -----重写原型链-----:
// 即在通过原型链实现继承时,不能使用对象字面量创建原型方法。因为这样做就会重写原型链
function SuperType() {
this.property = true;
}
SuperType.prototype.getSuperValue = function() {
return this.property;
};
function SubType() {
this.subproperty = false;
}
//inherit from SuperType
SubType.prototype = new SuperType();
// 使用字面量添加新方法,会导致上一行代码无效
// 现在的原型包含的是一个Object的实例,而非SuperType的实例
SubType.prototype = {
getSubValue: function() {
return this.subproperty;
},
someOtherMethod: function() {
return false;
}
};
var instance = new SubType();
console.log(instance.getSuperValue()); //error!
// -----含有引用类型值的原型问题-----:
// 1. 包含引用类型值的原型属性会被所有实例共享(因此应该在构造函数里定义引用类型属性)
// 2. 没有办法在不影响所有对象实例的情况下,给超类型的构造函数传递参数
function SuperType() {
this.colors = ["red", "blue", "green"];
}
function SubType() {}
//inherit from SuperType
SubType.prototype = new SuperType();
var instance1 = new SubType();
instance1.colors.push("black");
console.log(instance1.colors); //"red,blue,green,black"
var instance2 = new SubType();
console.log(instance2.colors); //"red,blue,green,black"
// -----借用构造函数模式-----:
// 函数只不过是在特定环境中执行代码的对象,
// 因此通过使用apply()和call()方法也可以在(将来)新创建的对象上执行构造函数,
function SuperType() {
this.colors = ["red", "blue", "green"];
}
function SubType() {
// 实际上是在(未来将要)新创建的SubType实例的环境下调用了SuperType构造函数
SuperType.call(this);
}
var instance1 = new SubType();
instance1.colors.push("black");
alert(instance1.colors); //"red,blue,green,black"
var instance2 = new SubType();
alert(instance2.colors); //"red,blue,green"
// 还可以在子类构造器函数中向超类型构造函数传递参数。如下:
function SuperType(name) {
this.name = name;
}
function SubType() {
// 继承了SuperType,还传递了参数
SuperType.call(this, "Nicholas");
//instance property
this.age = 29;
}
var instance = new SubType();
alert(instance.name); //"Nicholas";
alert(instance.age); //29
// -----借用构造函数模式的问题-----:
// 1. 方法都在构造函数中定义,因此函数复用就无从谈起了。
// 2. 而且,在超类型的原型中定义的方法,对子类型而言也是不可见的,
// -----组合继承-----:
// 组合继承避免了原型链和借用构造函数的缺陷,融合了它们的优点,成为JavaScript中最常用的继承模式。
function SuperType(name) {
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function() {
alert(this.name);
};
function SubType(name, age) {
SuperType.call(this, name);
this.age = age;
}
SubType.prototype = new SuperType();
SubType.prototype.sayAge = function() {
alert(this.age);
};
var instance1 = new SubType("Nicholas", 29);
instance1.colors.push("black");
alert(instance1.colors); //"red,blue,green,black"
instance1.sayName(); //"Nicholas";
instance1.sayAge(); //29
var instance2 = new SubType("Greg", 27);
alert(instance2.colors); //"red,blue,green"
instance2.sayName(); //"Greg";
instance2.sayAge(); //27
// -----原型式继承-----:
// 本质上object()对传入其中的对象执行了一次浅复制。
function object(o) {
function F() {}
F.prototype = o;
return new F();
}
// 增加如下代码
var person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
// 返回的这个新对象将person作为原型,
// 所以它的原型中就包含一个基本类型值属性和一个引用类型值属性。
var anotherPerson = object(person);
anotherPerson.name = "Greg";
anotherPerson.friends.push("Rob");
var yetAnotherPerson = object(person);
yetAnotherPerson.name = "Linda";
yetAnotherPerson.friends.push("Barbie");
alert(person.friends); //"Shelby,Court,Van,Rob,Barbie"
// ECMAScript5通过新增Object.create()方法规范化了原型式继承。
// 这个方法接收两个参数:一个用作新对象原型的对象和(可选的)一个为新对象定义额外属性的对象。
// 在传入一个参数的情况下,Object.create()与object()方法的行为相同。
// 其实说白了,就是将传进去的对象,作为新返回对象的原型而已
var person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
var anotherPerson = Object.create(person);
anotherPerson.name = "Greg";
anotherPerson.friends.push("Rob");
var yetAnotherPerson = Object.create(person);
yetAnotherPerson.name = "Linda";
yetAnotherPerson.friends.push("Barbie");
alert(person.friends); //"Shelby,Court,Van,Rob,Barbie"
// Object.create()参数二与Object.defineProperties()方法的第二个参数格式相同:
// 每个属性都是通过自己的描述符定义的。
var person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
var anotherPerson = Object.create(person, {
name: {
value: "Greg"
}
});
alert(anotherPerson.name); //"Greg"
// -----寄生式继承-----:
// 寄生式继承的思路与寄生构造函数和工厂模式类似,
// 即创建一个仅用于封装继承过程的函数,
// 该函数在内部以某种方式来增强对象,
// 最后再像真地是它做了所有工作一样返回对象。
function createAnother(original) {
var clone = object(original); // 创建一个新对象
clone.sayHi = function() {
// 某种方式增强对象
console.log("hi");
};
return clone; // 返回新对象
}
// -----组合式继承-----:
// 寄生式继承的缺点:为对象添加函数,会由于不能做到函数复用而降低效率
function SuperType(name) {
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function() {
alert(this.name);
};
function SubType(name, age) {
SuperType.call(this, name); // 第二次调用SuperType()
this.age = age;
}
SubType.prototype = new SuperType(); // 第一次调用SuperType()
var instance = new SubType("Nicholas", 29);
// 分析过程:
// 1. 在第一次调用SuperType构造函数时,SubType.prototype会得到两个属性:name和colors;
// 2. 它们都是SuperType的实例属性,只不过现在位于SubType的原型中。
// 3. 当调用SubType构造函数时,又会调用一次SuperType构造函数,
// 4. 这一次又在新对象上创建了实例属性name和colors。于是,这两个属性就屏蔽了原型中的两个同名属性。
// 结果:有两组name和colors属性:一组在实例上,一组在SubType原型中。
// 具体参考图6-6
// -----寄生组合式继承-----:
// 即通过借用构造函数来继承属性,通过原型链的混成形式来继承方法。
// 其背后的基本思路是:不必为了指定子类型的原型而调用超类型的构造函数,
// 我们所需要的无非就是超类型原型的一个副本而已。
// 如下是一个基本模式
function inheritPrototype(subType, superType) {
var prototype = object(superType.prototype); //create object
prototype.constructor = subType; //augment object
subType.prototype = prototype; //assign object
}
// 整体写下来如下:
function object(o) {
function F() {}
F.prototype = o;
return new F();
}
function inheritPrototype(subType, superType) {
var prototype = object(superType.prototype); // 创建对象
prototype.constructor = subType; // 增强对象
subType.prototype = prototype; // 指定对象
}
function SuperType(name) {
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function() {
alert(this.name);
};
function SubType(name, age) {
SuperType.call(this, name);
this.age = age;
}
inheritPrototype(SubType, SuperType);
SubType.prototype.sayAge = function() {
alert(this.age);
};
var instance1 = new SubType("Nicholas", 29);
instance1.colors.push("black");
alert(instance1.colors); //"red,blue,green,black"
instance1.sayName(); //"Nicholas";
instance1.sayAge(); //29
var instance2 = new SubType("Greg", 27);
alert(instance2.colors); //"red,blue,green"
instance2.sayName(); //"Greg";
instance2.sayAge(); //27
// 这个方案只调用了一次SuperType构造函数
// 并且因此避免了在SubType.prototype上面创建不必要的、多余的属性。
// 与此同时,原型链还能保持不变;因此,还能够正常使用instanceof和isPrototypeOf()。
// 开发人员普遍认为寄生组合式继承是引用类型最理想的继承范式。
// 总结
// ECMAScript支持面向对象(OO)编程,但不使用类或者接口。
// 对象可以在代码执行过程中创建和增强,因此具有动态性而非严格定义的实体。
// 在没有类的情况下,可以采用下列模式创建对象。
// 工厂模式,
// 使用简单的函数创建对象,为对象添加属性和方法,然后返回对象。
// 这个模式后来被构造函数模式所取代。
// 构造函数模式,
// 可以创建自定义引用类型,可以像创建内置对象实例一样使用new操作符。
// 不过,构造函数模式也有缺点,即它的每个成员都无法得到复用,包括函数。
// 由于函数可以不局限于任何对象(即与对象具有松散耦合的特点),因此没有理由不在多个对象间共享函数。
// 原型模式,
// 使用构造函数的prototype属性来指定那些应该共享的属性和方法。
// 组合使用构造函数模式和原型模式时,使用构造函数定义实例属性,而使用原型定义共享的属性和方法。
// JavaScript主要通过原型链实现继承。
// 原型链的构建是通过将一个类型的实例赋值给另一个构造函数的原型实现的。
// 这样,子类型就能够访问超类型的所有属性和方法,这一点与基于类的继承很相似。
// 原型链的问题是对象实例共享所有继承的属性和方法,因此不适宜单独使用。
// 解决这个问题的技术是借用构造函数,即在子类型构造函数的内部调用超类型构造函数。
// 这样就可以做到每个实例都具有自己的属性,同时还能保证只使用构造函数模式来定义类型。
// 使用最多的继承模式是组合继承,这种模式使用原型链继承共享的属性和方法,而通过借用构造函数继承实例属性。
// 此外,还存在下列可供选择的继承模式。
// 原型式继承,
// 可以在不必预先定义构造函数的情况下实现继承,其本质是执行对给定对象的浅复制。
// 而复制得到的副本还可以得到进一步改造。
// 寄生式继承,
// 与原型式继承非常相似,也是基于某个对象或某些信息创建一个对象,然后增强对象,最后返回对象。
// 为了解决组合继承模式由于多次调用超类型构造函数而导致的低效率问题,可以将这个模式与组合继承一起使用。
// 寄生组合式继承,
// 集寄生式继承和组合继承的优点与一身,是实现基于类型继承的最有效方式。
// 测试题
function A(name){
// 实例化的时候没有传参,因此此时name为undefined
// 也就是实例上不会执行if
if(name){
this.name = name;
}
}
A.prototype.name = 'jack';
var a = new A();
console.log(a.name); // 'jack'
function B(name){
// 实例化时没有传参,但赋值了,为undefined
this.name = name;
}
B.prototype.name = 'jack';
var b = new B();
console.log(b.name); // undefined
函数
arguments
ECMAScript 函数可以封装任意多条语句,且不介意传进来多少参数,什么数据类型,即便定义的参数与实际调用时传递的数量不一致也没有关系,因为 ECMAScript 中的参数在内部是用一个伪数组来表示,这便是arguments对象,具有 length 属性但并不是数组的实例(也不具有数组常用 api)。
ECMAScript 函数中命名的参数只是提供便利,但不是必需。另外,在命名参数方面,其他语言可能需要事先创建一个函数签名,而将来的调用必需与该签名一致,但 ECMAScript 函数并没有此要求,因此 ECMAScript 函数也不能重载(其实可以理解为同名函数,根据参数名的不同分别执行多次,但在 js 中同名函数会有覆盖且参数是伪数组,因此无法重载,但可以根据参数个数不同实现不同的逻辑,进而模拟重载)。
function doAdd(num1, num2) {
arguments[1] = 20;
console.log(arguments[0] + num2);
}
doAdd(10, 10); // 30
修改arguments[1]会自动映射到 num2 上,因为arguments对象中的值会自动映射到对应的命名参数。但注意:并不是说这两个值访问相同的内存空间,他们的内存空间是独立的,但值会同步。
有地方说,上述影响是单向的,即修改arguments会自动映射到对应的命名参数,反之不行?但下面代码在 chrome 可行,也就是说这种改变是双向的。。。
function test(num1, num2) {
arguments[1] = 20;
console.log(num2);
num2 = 40;
console.log(arguments[1]);
}
test(); // 20 40
但在严格模式下,会有些不同,即arguments对象变化时不再与对应的命名参数自动同步值,如下:
function test(num1, num2) {
"use strict";
arguments[1] = 20;
console.log(num2);
num2 = 40;
console.log(arguments[1]);
}
test(); // 2 20
函数中参数传递
。ECMAScript 中所有函数的参数都是按值传递的。也就是说,把函数外部的值赋值给函数内部的参数,就和把值从一个变量复制到另一个变量一样,即使针对引用类型,也只是将指向内存的地址给复制了一份。访问变量有按值和按引用两种方式,但参数传递只能按值传递。
在向参数传递引用类型的值时,会把这个值在内存中的地址复制给一个局部变量,因为这个局部变量里的地址仍然指向外部的那个对象,因此局部变量的变化会反映在函数的外部。
function setName(obj) {
obj.name = "Nicholas";
obj.name = "Change";
}
var person = new Object();
setName(person);
console.log(person.name); // "Nicholas"
如上,只是把person对象在内存中的地址当做参数传给函数了,当执行obj.name = "Nicholas";时,局部变量obj和person确实都指向同一块内存空间。但执行obj = new Object();时,新创建一个内存空间的地址赋值给了局部变量obj(也会在函数执行完毕后被销毁),但并没有影响函数外person对象的指向啊,因此依然打印"Nicholas"。。。这就证明了:ECMAScript 中所有函数的参数都是按值传递的
Ajax 与 Comet
Ajax 简介
2005 年,JesseJamesGarrett发表了一篇在线文章,题为“Ajax:A new Approach to Web Applications”。他在这篇文章里介绍了一种技术,用他的话说,就叫Ajax,是对 Asynchronous JavaScript+ XML的简写。这一技术能够向服务器请求额外的数据而无须卸载页面,会带来更好的用户体验。Garrett还解释了怎样使用这一技术改变自从 Web 诞生以来就一直沿用的“单击,等待”的交互模式。
性能优化
首屏加载
首屏加载……骨架屏,ssr,cdn,prefetch,preload(早于页面请求)等。。。加载后的资源可以设置强制或协商缓存
管理内存
。使用具备垃圾回收机制的语言编写程序,开发人员不用担心内存管理问题,但 js 在进行内存管理与垃圾回收方面面临的问题还是有点与众不同。
其中最主要的问题是:分配给 web 浏览器的可用内存数量通常比桌面程序要少,这是出于安全考虑,目的就是防止运行 js 的网页耗尽全部系统内存而导致系统崩溃。内存限制问题,不但影响给变量分配内存,同时还会影响调用栈以及一个线程中能够同时执行的语句数量。
因此为了提高性能,降低不必要的内存占用,一旦数据不再使用,最好通过将其值设为null来释放引用,适用于大多数全局变量和全局对象的属性,局部变量会在它们离开环境时自动解除引用。
。注意:解除引用并不意味着自动回收该值占用的空间,而是让值脱离执行环境,以便垃圾回收器下次运行时将其回收